4.2 Network permutation
4.2.1 Node permutationの手法
Network permutationには大きく分けて辺をシャッフルするedge permutationと、ノードをシャッフルするnode permutationに分けられるが、本節ではより一般的に用いられている後者についてのみ解説を行う。前者は生物のネットワークではあまり用いられないため(D. P. Croft et al., 2011; Farine, 2017)、ここでは解説しない。
Node permutationでは、ノードの属性(性別、順位など)をランダムにシャッフルして生成したランダムなネットワークにおける統計検定量の分布を帰無分布とし、実際のデータの統計検定量をそれと比較することで有意性を判定する方法である。これにより、ネットワークの構造(e.g., ノード数、辺の数、密度など)や属性ごとのノード数(e.g., 性別の場合、オスとメスの数)を一定にしたまま検定を行うことができる。
例えば、5個体からなる集団において、個体の社会的順位と固有ベクトル中心性の相関の有意性を検定するとしよう。Node permutationでは、以下のような手順で検定を行う(4.1も参照)。
観察データからネットワークを生成する。
ここでは、図4.2のORIGINALが得られたとする1で作成した社会ネットワークに対して統計分析を行い、統計検定量を算出する。
ここでは相関係数を算出し、-0.83だったとする(図4.2)。ノードの属性(ここでは個体名とその順位)をランダムにシャッフルし、ランダムネットワークを多数作成する(図4.2のPERMUTATION1 ~ PERMUTATION1000)。通常は少なくとも1000回は行う。
すべてのランダムなネットワークにおける相関係数を算出する(図4.2)。
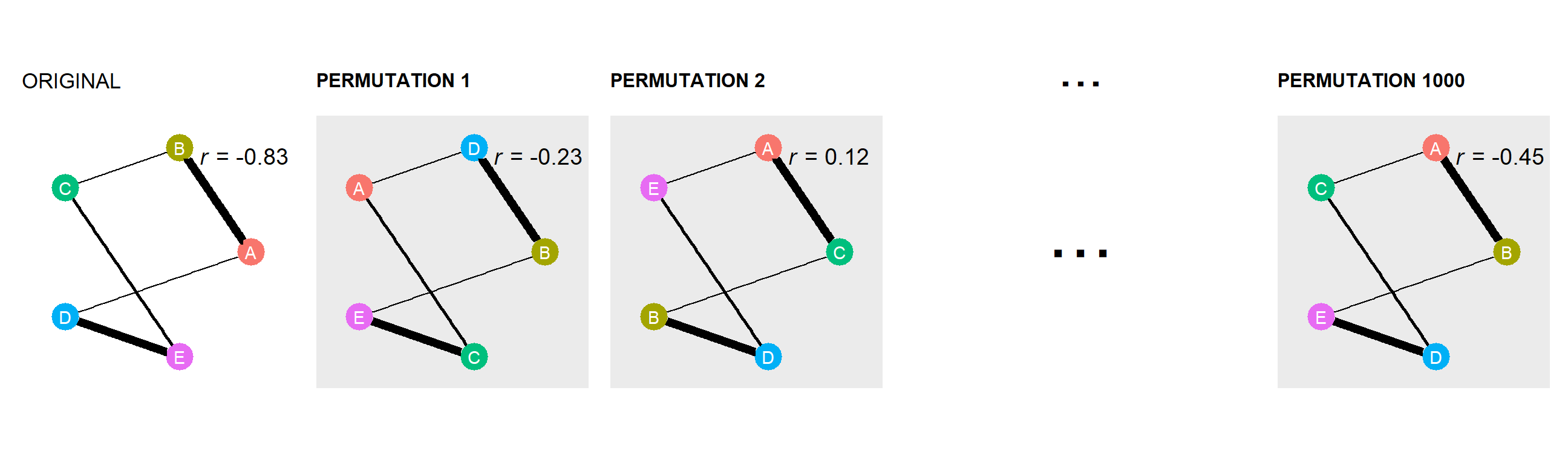
図4.2: Node permutationの例
- ランダムなネットワークから算出された相関係数の分布を帰無分布とし、実際の相関係数がこれらの何%より大きい(または小さい)かを算出する(図4.3)。これが\(P\)値になる。このように、片側検定が用いられることが多い。ここでは、ランダムネットワークの相関係数の5/1000しか実測値より小さくないので、\(P = 0.005\)となり有意な負の相関があるという結論が得られる。
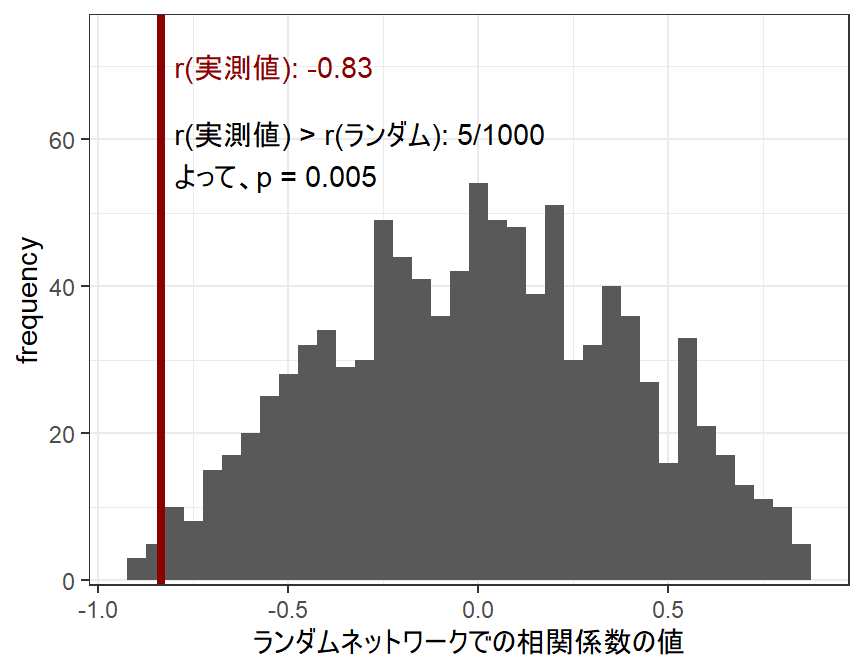
図4.3: Node permutationでの検定の例
4.2.2 分析例
Node permutationは様々な分析に適用可能である。以下では、実際の分析例をいくつか見ていく。
4.2.2.1 線形モデル(GLM、GLMMなど)
一般化線形モデル(GLM)や一般化線形混合モデル(GLMM)をはじめとした線形モデルは、2つ以上の変数間の関連を調べるうえで非常に有用な分析である(Dunn & Smyth, 2018; 大東, 2010)。これらの手法は、社会ネットワーク分析でノードレベルの検定(e.g., 各個体の属性と中心性指標の関連など)を行う際にも非常に有用である(Farine, 2017)。
GLMやGLMMでは、何かの原因となっていると想定される変数を説明変数(以下、\(x\)とする)、それを受けて変化すると想定される変数を応答変数(以下、\(y\)とする)という。
4.2.2.1.1 分析例1. 正規線形モデル
以下では、シンプルな例として応答変数が正規分布から得られていると仮定するモデルを用いた分析を行う。金華山島\(B_1\)群において、個体追跡中の6歳以上のメス間の近接時間割合を算出したところ、以下の隣接行列(prox_mat, 4.1)が得られたとする。
## マトリックスの読み込み
prox_mat <- read.csv("data/prox_f.csv",row.names=1) %>%
as.matrix()
## マトリックスをアルファベット順で並び替え
prox_mat <- prox_mat[sort(rownames(prox_mat)), sort(colnames(prox_mat))]
## 体格成分を0に
diag(prox_mat) <- 0 | Aka | Ako | Hen | Hot | Kil | Kit | Koh | Kor | Kun | Mal | Mei | Mik | Ntr | Ten | Tot | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aka | 0.00 | 0.07 | 0.01 | 0.02 | 0.01 | 0.00 | 0.02 | 0.02 | 0.01 | 0.01 | 0.03 | 0.03 | 0.05 | 0.06 | 0.02 |
| Ako | 0.07 | 0.00 | 0.05 | 0.02 | 0.02 | 0.02 | 0.01 | 0.03 | 0.01 | 0.01 | 0.04 | 0.02 | 0.04 | 0.03 | 0.02 |
| Hen | 0.01 | 0.05 | 0.00 | 0.04 | 0.01 | 0.01 | 0.02 | 0.03 | 0.00 | 0.03 | 0.03 | 0.04 | 0.03 | 0.02 | 0.06 |
| Hot | 0.02 | 0.02 | 0.04 | 0.00 | 0.01 | 0.01 | 0.00 | 0.02 | 0.05 | 0.03 | 0.02 | 0.04 | 0.01 | 0.04 | 0.03 |
| Kil | 0.01 | 0.02 | 0.01 | 0.01 | 0.00 | 0.15 | 0.11 | 0.05 | 0.03 | 0.02 | 0.01 | 0.04 | 0.04 | 0.03 | 0.02 |
| Kit | 0.00 | 0.02 | 0.01 | 0.01 | 0.15 | 0.00 | 0.10 | 0.06 | 0.06 | 0.01 | 0.02 | 0.03 | 0.04 | 0.03 | 0.04 |
| Koh | 0.02 | 0.01 | 0.02 | 0.00 | 0.11 | 0.10 | 0.00 | 0.09 | 0.06 | 0.01 | 0.01 | 0.03 | 0.02 | 0.02 | 0.04 |
| Kor | 0.02 | 0.03 | 0.03 | 0.02 | 0.05 | 0.06 | 0.09 | 0.00 | 0.04 | 0.02 | 0.03 | 0.05 | 0.06 | 0.07 | 0.13 |
| Kun | 0.01 | 0.01 | 0.00 | 0.05 | 0.03 | 0.06 | 0.06 | 0.04 | 0.00 | 0.04 | 0.00 | 0.02 | 0.02 | 0.04 | 0.01 |
| Mal | 0.01 | 0.01 | 0.03 | 0.03 | 0.02 | 0.01 | 0.01 | 0.02 | 0.04 | 0.00 | 0.05 | 0.15 | 0.03 | 0.04 | 0.02 |
| Mei | 0.03 | 0.04 | 0.03 | 0.02 | 0.01 | 0.02 | 0.01 | 0.03 | 0.00 | 0.05 | 0.00 | 0.03 | 0.05 | 0.03 | 0.02 |
| Mik | 0.03 | 0.02 | 0.04 | 0.04 | 0.04 | 0.03 | 0.03 | 0.05 | 0.02 | 0.15 | 0.03 | 0.00 | 0.03 | 0.05 | 0.02 |
| Ntr | 0.05 | 0.04 | 0.03 | 0.01 | 0.04 | 0.04 | 0.02 | 0.06 | 0.02 | 0.03 | 0.05 | 0.03 | 0.00 | 0.07 | 0.03 |
| Ten | 0.06 | 0.03 | 0.02 | 0.04 | 0.03 | 0.03 | 0.02 | 0.07 | 0.04 | 0.04 | 0.03 | 0.05 | 0.07 | 0.00 | 0.07 |
| Tot | 0.02 | 0.02 | 0.06 | 0.03 | 0.02 | 0.04 | 0.04 | 0.13 | 0.01 | 0.02 | 0.02 | 0.02 | 0.03 | 0.07 | 0.00 |
このネットワークにおいて、各メスの固有ベクトル中心性(eigen)と順位(rank)・年齢(age)との関連を調べるため、以下のモデルを考える。ただし、添え字の\(i\)はそれが\(i\)番目の個体のデータであることを表す(\(i = 1,2,3,...,16\))。
\(\beta_0\)はモデルの切片を、\(\beta_1\)と\(\beta_2\)はそれぞれ順位と年齢が1増えたときに、固有ベクトル中心性がどのくらい上昇すると期待されるかを表す(= 回帰係数)。また、2行目の数式は、\(i\)番目の個体の固有ベクトル中心性(\(eigen_i\))が、平均\(\mu_i\)、分散\(\sigma\)の正規分布から得られることを表す。GLMやGLMMでは、実際のデータが得られる確率が最も高くなるようにモデルのパラメータ(ここでは、\(\beta_0, \beta_1, \beta_2. \sigma\))を推定していく。
\[ \begin{aligned} \mu_i &= \beta_0 + \beta_1 \times rank_i + \beta_2 \times age_i \\ eigen_i &\sim Normal(\mu_i, \sigma) \end{aligned} \]
それでは、分析に移ろう。すでに隣接行列を算出してネットワークを作成しているので、個体ごとの固有ベクトル中心性を算出する(Step2)。個体ごとの属性をatt_femalesとしてデータフレームにまとめる(第2.2参照)。
## 属性データの作成
att_females <- data.frame(femaleID = colnames(prox_mat),
rank = c(8,9,11,12,1,2,3,5,4,13,15,14,6,7,10),
age = c(12,9,10,10,14,7,12,8,6,8,10,15, 10, 10, 10))
## 算出
att_females <- met.eigen(prox_mat,
df = att_females,
dfid = 1,
sym = TRUE)算出結果は以下のようになった。

図4.4: 固有ベクトル中心性(eigen)と順位(rank)・年齢(age)との関連
続いて、先ほどの数式に基づいたモデリングを行う。Rでは以下のコードで実行することができる。
モデリングの結果推定された\(\beta_0\)、\(\beta_1\)、\(\beta_2\)の推定値は以下のようになる。なお、Interceptは切片を表す。
##
## Call:
## lm(formula = eigen ~ rank + age, data = att_females)
##
## Coefficients:
## (Intercept) rank age
## 0.76715 -0.02341 0.01126パーミュテーション検定では、\(\beta_1\)や\(\beta_2\)などの回帰係数を統計検定量として検定を行うことで、説明変数と応答変数の関連が有意であるかをしらべることが推奨されている(Farine, 2017)。そこで、それぞれの推定値を持つオブジェクトを作成する(b_rankとb_age)。
4.2.2.1.1.1 snaパッケージを用いる方法
続いて、node permutationを行ってランダムなネットワーク(隣接行列)を1000個生成し、それぞれのネットワークにおいて同じ回帰分析を行い、先ほど同様に\(\beta_1\)と\(\beta_2\)の推定値を算出する(Step3~4)。
Rでは、snaパッケージのrmperm関数でnode permutationを行うことができる。b_rank_randとb_rank_ageという空のベクトルを作成し、そこにランダムネットワークから算出された\(\beta_1\)と\(\beta_2\)を入れている。
## 空の行列を作成
b_rank_rand <- rep(0,1000)
b_age_rand <- rep(0,1000)
set.seed(123)
for(i in 1:1000){
random_net <- rmperm(prox_mat)
att_females_rand <- met.eigen(random_net, df = att_females)
r_lm_rand <- lm(data = att_females_rand,
formula = eigen ~ rank + age)
b_rank_rand[i] <- coef(r_lm_rand)[[2]]
b_age_rand[i] <- coef(r_lm_rand)[[3]]
}それでは、最後に実データの回帰係数をランダムネットワークの回帰係数の分布と比較する(図4.5)。灰色のヒストグラムがランダムネットワークの回帰係数の分布を、赤い線が実データの回帰係数を表している。\(\beta_1\)については、有意な値だといえそうだ。
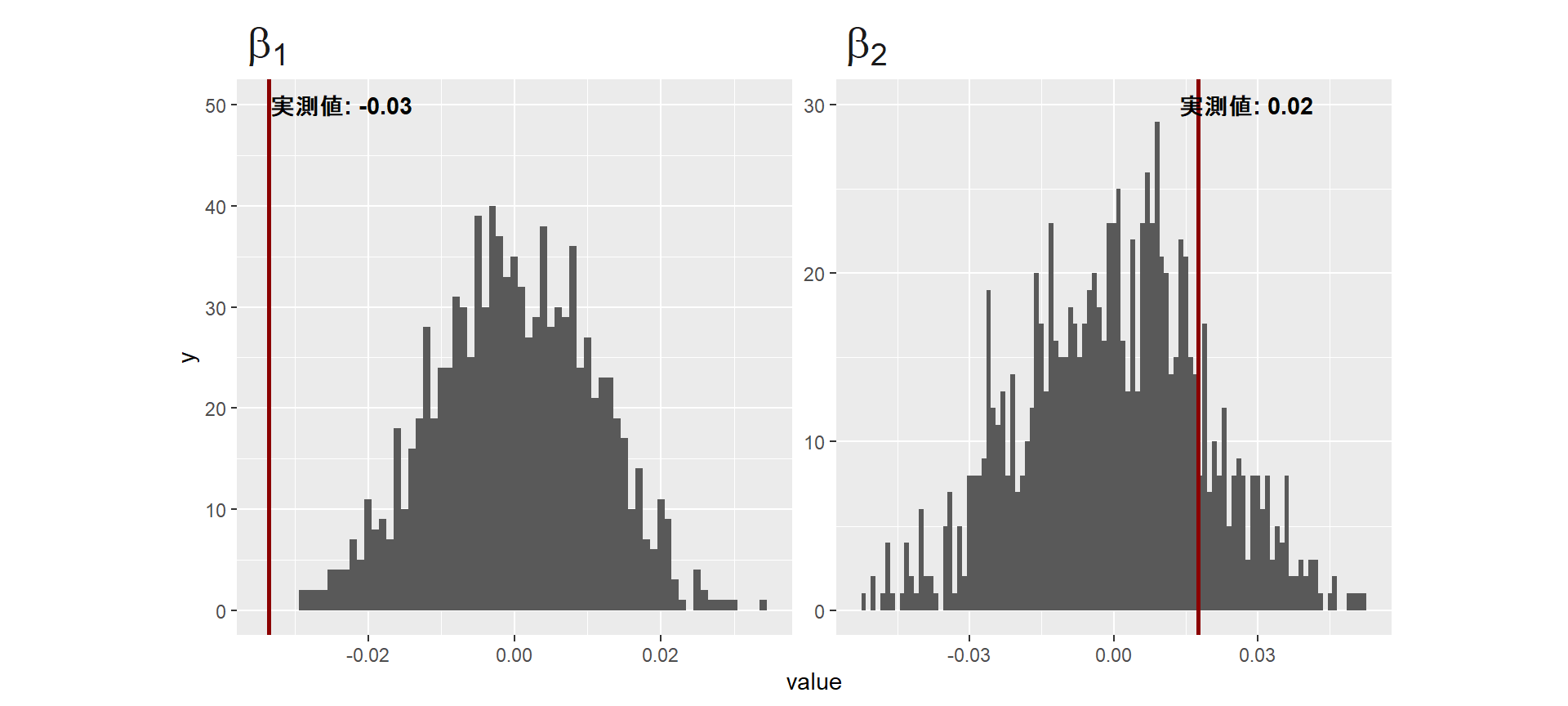
図4.5: 実データの回帰係数とランダムネットワークの回帰係数の分布の比較
そこで、実データの回帰係数がランダムネットワークの回帰係数の何%より大きいか/小さいかを計算することで、\(P\)値を算出する。
算出は以下のように行える。
順位の係数(\(\beta_1\))については、P = 0.000なので、有意な関連があると結論付けられる。
## [1] 0一方で、年齢の係数(\(\beta_2\))については、P = 0.832なので、帰無仮説は棄却されない。
## [1] 0.8324.2.2.1.1.2 ANTsパッケージを用いる方法
ここまで行ったnode permutation検定のstep3以降は、ANTsパッケージを用いるとより簡単に行うことができる。
ANTsパッケージでは、個体の属性や中心性指標が入ったデータフレームを用いて、node permutationを行うことができる。
perm.net.nl関数では、指定されたラベル(今回の場合は、応答変数である固有ベクトル中心性)について、指定した数だけパーミュテーションを行ってくれる(やっていることはsnaパッケージを用いた場合と同じ)。
set.seed(123)
perm_lm <- perm.net.nl(## 算出した固有ベクトル中心性と属性を含むデータフレーム
att_females,
## パーミュテーションするラベル。ここでは固有ベクトル中心性
labels = c("eigen"),
## 回数
nperm = 1000,
progress = FALSE)続いてstat.glm関数を用い、実データとランダムネットワークにおけるデータに対してモデリングを行い、パラメータの推定値を算出する。 このとき、相関係数の検定についてはstat.cor、t検定についてはstat.t、GLMMについてはstat.glmmなど、分析ごとに様々な関数が用意されている。詳細はこちらのサイトを参照。
r_lm_b <- stat.glm(perm_lm,
## 式
formula = eigen ~ age + rank,
## 応答変数が従う分布を指定。二項分布なら"binomial"、ポワソン分布なら"poisson"
family = "gaussian",
progress = FALSE)## Original model :
##
##
## Call:
## "eigen ~ age + rank , family = gaussian"
##
## Coefficients:
## Estimate Std. Error t value
## (Intercept) 0.767149 0.177280 4.327
## age 0.011258 0.016630 0.677
## rank -0.023405 0.009051 -2.586
##
## (Dispersion parameter for gaussian family taken to be 0.02250086)
##
## Null deviance: 0.42284 on 14 degrees of freedom
## Residual deviance: 0.27001 on 12 degrees of freedom
## AIC: -9.692
##
## Number of Fisher Scoring iterations: 2分析結果は、ant関数を用いることで確認できる。
モデルの診断プロット(残差 vs 予測値、QQプロット)および実データの回帰係数とランダムネットワークの回帰係数の分布の比較は以下のように可視化できる。
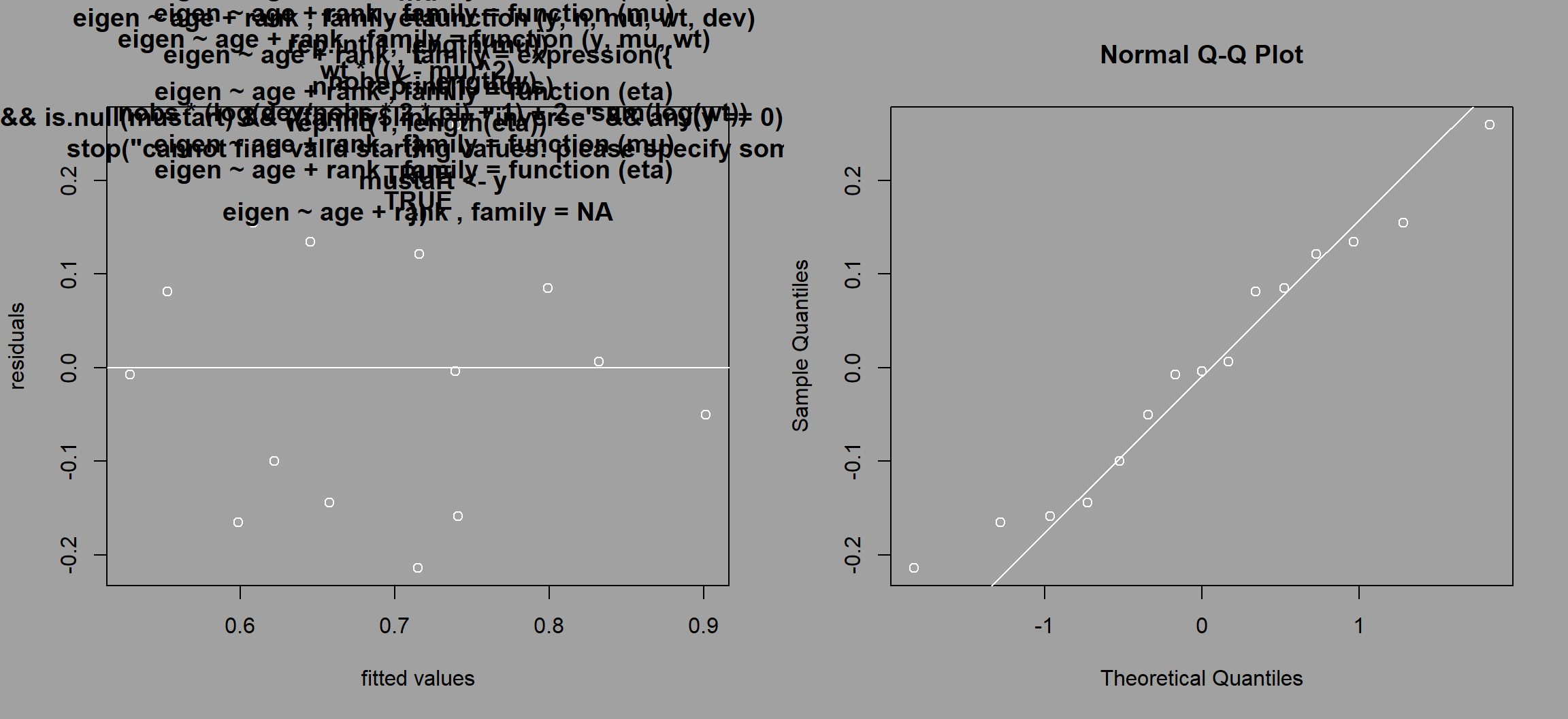
図4.6: 実データの回帰係数とランダムネットワークの回帰係数の分布の比較
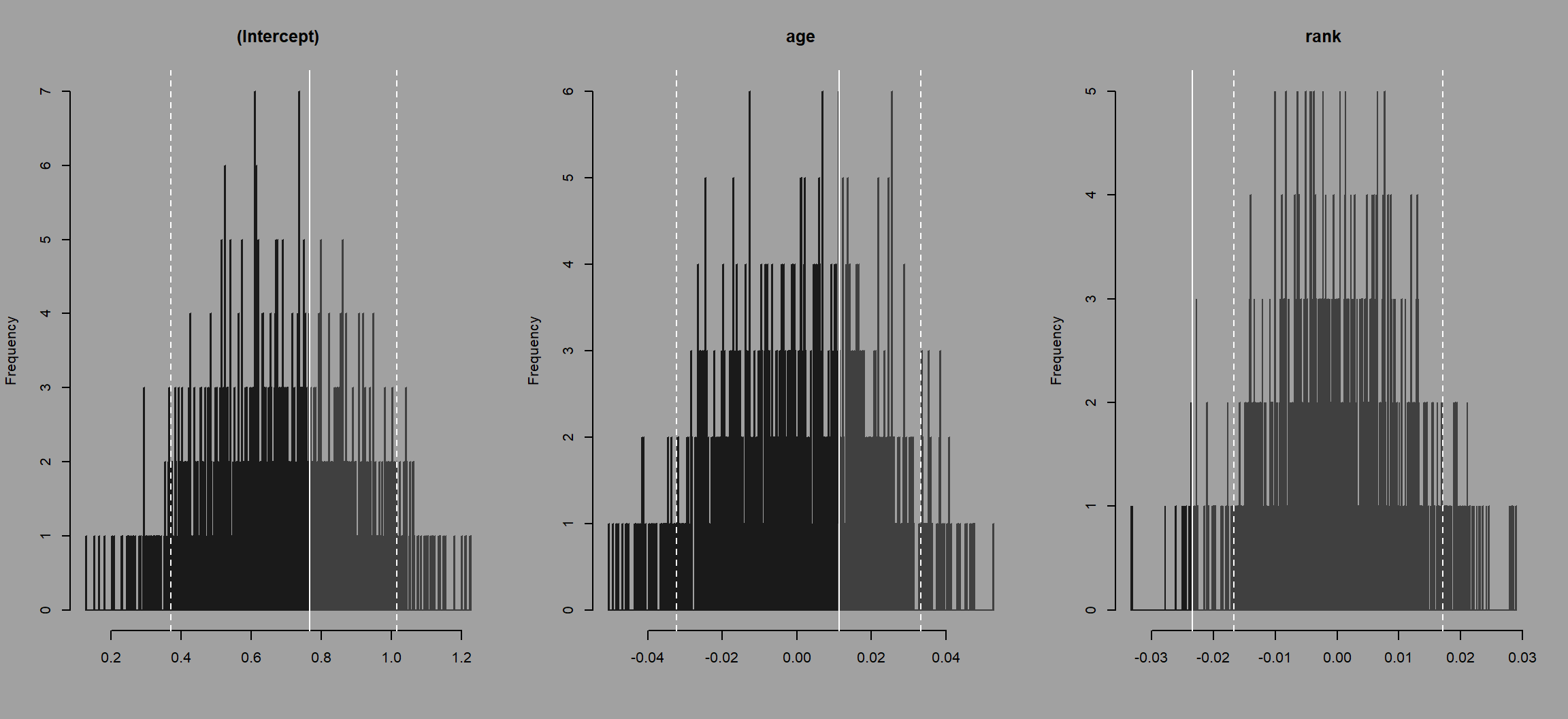
図4.7: 実データの回帰係数とランダムネットワークの回帰係数の分布の比較
検定結果は以下の通り。p.leftとp_rightはランダムネットワークの係数が実際の係数よりも小さい/大きい確率を表す。snaパッケージを用いた場合と概ね同じ結果が得られている。
## Estimate Std. Error t value p.left p.rigth p.two.sides
## (Intercept) 0.76714876 0.17728013 4.3273252 0.639 0.361 0.722
## age 0.01125765 0.01663024 0.6769383 0.707 0.293 0.586
## rank -0.02340526 0.00905074 -2.5860055 0.012 0.988 0.024
## lower.ci uper.ci mean
## (Intercept) 0.37160954 1.01698268 6.923941e-01
## age -0.03231765 0.03319796 7.270721e-05
## rank -0.01674872 0.01713235 1.345814e-05モデルの診断結果をr_lm_ants$model.diagnosticで調べることもできる。
4.2.2.1.2 分析例2. 線形混合モデル
同様の分析は、モデルにランダム効果を入れたGLMMなどの混合モデルについても適用できる。GLMMについては、こちら などを参照。複数の調査期間に/複数の集団でデータを収集した場合などにすべてのデータをまとめて分析する際には、GLMMが適用される(Sosa et al., 2020)。
例えば、ニホンザルの7つの集団(A~F)である年におけるメスの毛づくろいのデータを収集し、ダイアッドごとの毛づくろい頻度を算出したとしよう。以下のlist_matには、list形式で7つの隣接行列が収納されている(架空のデータである)。
例えば、3つ目の集団(C)の隣接行列は以下のようになっている(表4.3。
list_mat[[3]] %>%
kable(digits = 2, align = "c", caption = "3つめの隣接行列") %>%
kable_styling(font_size = 5, full_width = FALSE)| 0.00 | 0.81 | 1.43 | 1.83 | 1.22 | 2.24 | 2.24 | 0.20 | 0.00 | 2.04 | 1.63 | 0.00 | 1.43 | 0.00 | 0.20 | 0.61 |
| 0.81 | 0.00 | 0.00 | 0.41 | 0.00 | 1.43 | 0.61 | 0.00 | 0.00 | 0.00 | 0.61 | 0.20 | 0.20 | 0.00 | 0.00 | 0.00 |
| 1.43 | 0.00 | 0.00 | 0.20 | 0.00 | 0.41 | 0.20 | 0.00 | 0.00 | 1.22 | 0.20 | 0.00 | 0.00 | 4.28 | 0.20 | 0.00 |
| 1.83 | 0.41 | 0.20 | 0.00 | 1.22 | 1.22 | 0.20 | 0.00 | 0.00 | 0.00 | 0.20 | 0.20 | 0.00 | 0.20 | 0.00 | 0.00 |
| 1.22 | 0.00 | 0.00 | 1.22 | 0.00 | 1.63 | 1.02 | 0.81 | 0.00 | 0.41 | 0.61 | 1.22 | 0.20 | 0.00 | 0.41 | 0.41 |
| 2.24 | 1.43 | 0.41 | 1.22 | 1.63 | 0.00 | 0.61 | 1.22 | 0.00 | 0.20 | 0.20 | 1.02 | 0.00 | 0.81 | 1.22 | 0.61 |
| 2.24 | 0.61 | 0.20 | 0.20 | 1.02 | 0.61 | 0.00 | 1.22 | 0.00 | 0.41 | 0.00 | 0.20 | 0.00 | 0.41 | 0.20 | 0.00 |
| 0.20 | 0.00 | 0.00 | 0.00 | 0.81 | 1.22 | 1.22 | 0.00 | 4.07 | 0.81 | 2.65 | 1.02 | 2.44 | 0.20 | 0.81 | 0.41 |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 4.07 | 0.00 | 0.81 | 0.81 | 0.20 | 3.05 | 1.22 | 1.02 | 2.24 |
| 2.04 | 0.00 | 1.22 | 0.00 | 0.41 | 0.20 | 0.41 | 0.81 | 0.81 | 0.00 | 0.61 | 0.81 | 2.85 | 0.20 | 0.61 | 0.81 |
| 1.63 | 0.61 | 0.20 | 0.20 | 0.61 | 0.20 | 0.00 | 2.65 | 0.81 | 0.61 | 0.00 | 2.04 | 0.20 | 0.41 | 2.85 | 2.85 |
| 0.00 | 0.20 | 0.00 | 0.20 | 1.22 | 1.02 | 0.20 | 1.02 | 0.20 | 0.81 | 2.04 | 0.00 | 0.61 | 0.20 | 1.22 | 1.43 |
| 1.43 | 0.20 | 0.00 | 0.00 | 0.20 | 0.00 | 0.00 | 2.44 | 3.05 | 2.85 | 0.20 | 0.61 | 0.00 | 0.20 | 0.81 | 0.61 |
| 0.00 | 0.00 | 4.28 | 0.20 | 0.00 | 0.81 | 0.41 | 0.20 | 1.22 | 0.20 | 0.41 | 0.20 | 0.20 | 0.00 | 0.41 | 0.41 |
| 0.20 | 0.00 | 0.20 | 0.00 | 0.41 | 1.22 | 0.20 | 0.81 | 1.02 | 0.61 | 2.85 | 1.22 | 0.81 | 0.41 | 0.00 | 2.65 |
| 0.61 | 0.00 | 0.00 | 0.00 | 0.41 | 0.61 | 0.00 | 0.41 | 2.24 | 0.81 | 2.85 | 1.43 | 0.61 | 0.41 | 2.65 | 0.00 |
これらの集団において、各個体の固有ベクトル中心性が、その後10年間の産子数に影響しているか調べたいとする。各集団における各メスの順位・年齢・産子数・集団名が以下のlist_attにlist形式で入っている(もちろん架空のデータである)。
例えば、C集団の属性データは以下のようになる。
さて、これらのデータに対して仮説(固有ベクトル中心性が、産子数に影響するか)を検証するために以下のモデルを考える。ただし、添え字の\(ji\)はそれが\(j\)番目の集団の\(i\)番目の個体のデータであることを表す。なお、eigen、rank、age、no_birthはそれぞれ固有ベクトル中心性、順位、年齢、産子数を表す。
\(r_j\)はランダム切片を表し、集団による産子数(no_birth)のばらつきがあることを示している。3行目の数式は、\(j\)番目の集団の\(i\)番目の個体の産子数(\(no\_birth_{ji}\))が、平均\(\lambda_{ji}\)のポワソン分布から得られることを表す。
\[ \begin{aligned} r_j &\sim Normal(0, \sigma)\\ \lambda_{ji} &= exp(\beta_0 + \beta_1 \times eigen_{ji} + \beta_2 \times rank_{ji} + \beta_3 \times age_{ji} + r_j) \\ no\_birth_{ji} &\sim Poisson(\lambda_{ji}) \end{aligned} \]
それでは、分析に移ろう。各集団ごとに固有ベクトル中心性を算出する(Step2)。ANTsパッケージでは、複数の隣接行列と属性データをそれぞれlist形式でまとめることで、以下のように複数のネットワークについて同時に中心性を算出できる。
C集団ついての算出結果は以下のようになった。
続いて、perm.net.nl関数を用いてnode permutationを行う(Step3)。今回のように複数のグループが含まれる集団では、各グループ内でnode permutationを行う。rf = "group"と指定してあげる。
perm_glmm <- perm.net.nl(list_att,
## 応答変数をシャッフルすることが多い
labels = "no_birth",
nperm = 1000,
rf = "group",
progress = FALSE)続いて、stat.glmm関数を用い、実データとランダムネットワークにおけるデータに対してモデリングを行い、パラメータの推定値を算出する(Step4)。ランダム切片は、(1|group)のように書いてformulaに加える。
r_glmm <- stat.glmm(perm_glmm,
## 式
formula = no_birth ~ eigen + rank + age + (1|group),
## 応答変数が従う分布を指定。二項分布なら"binomial"、ポワソン分布なら"poisson"
family = poisson(link = "log"),
progress = FALSE)## Original model :
##
## Generalized linear mixed model fit by maximum likelihood (Laplace
## Approximation) [glmerMod]
## Family: poisson ( log )
## Formula: no_birth ~ eigen + rank + age + (1 | group)
## Data: odf
##
## AIC BIC logLik deviance df.resid
## 444.3 458.7 -217.2 434.3 125
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.47385 -0.62718 -0.05524 0.57925 2.49088
##
## Random effects:
## Groups Name Variance Std.Dev.
## group (Intercept) 0.1195 0.3457
## Number of obs: 130, groups: group, 7
##
## Fixed effects:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.985451 0.266388 3.699 0.000216 ***
## eigen -0.021821 0.202649 -0.108 0.914251
## rank 0.067990 0.009907 6.863 6.74e-12 ***
## age -0.106731 0.020844 -5.120 3.05e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) eigen rank
## eigen -0.405
## rank -0.515 0.239
## age -0.616 0.042 0.011分析結果は、antパッケージを用いることで確認できる(Step5)。
モデルの診断プロット(残差 vs 予測値、QQプロット)および実データの回帰係数とランダムネットワークの回帰係数の分布の比較は以下のようになる。
図4.8: 実データの回帰係数とランダムネットワークの回帰係数の分布の比較
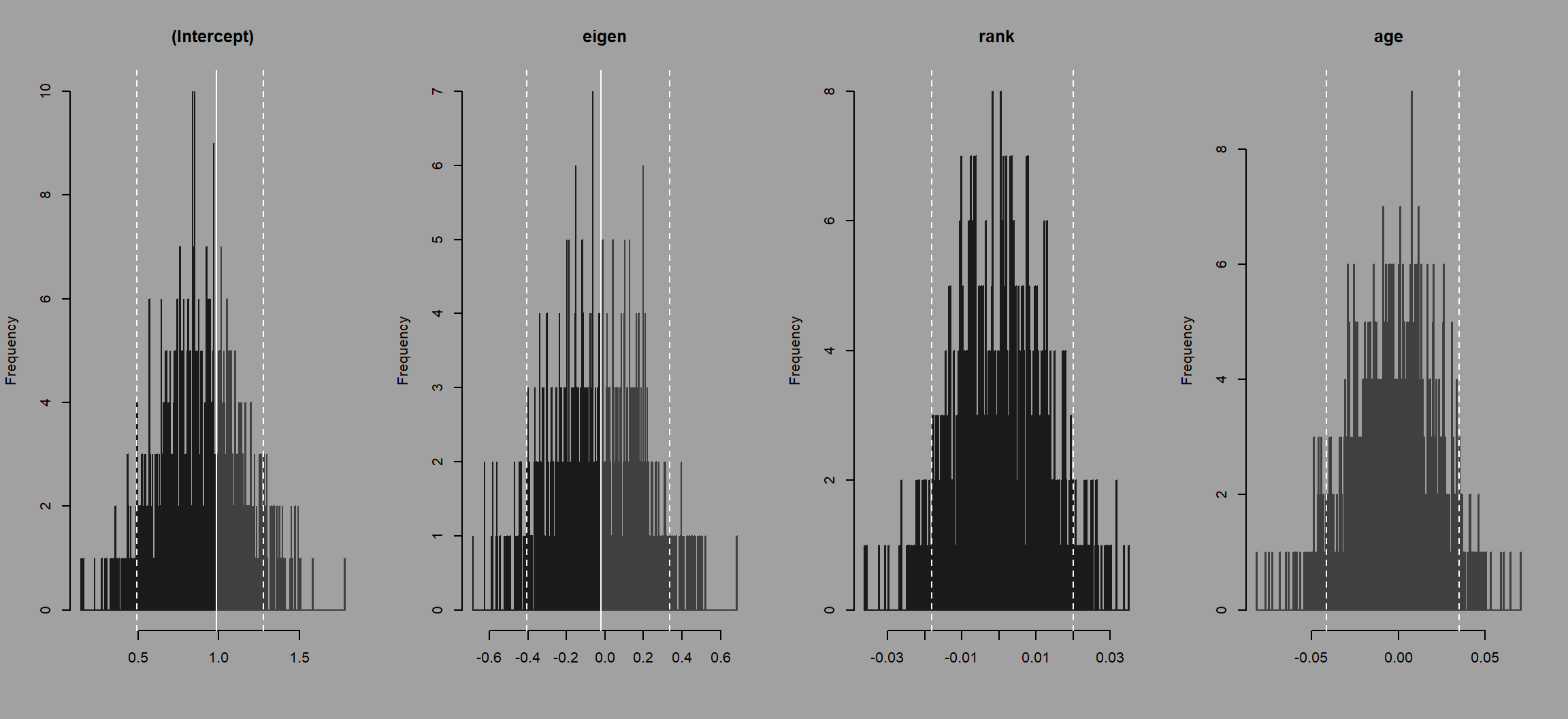
図4.9: 実データの回帰係数とランダムネットワークの回帰係数の分布の比較
検定結果は以下の通り。順位と年齢の有意な影響は確認されたが、固有ベクトル中心性の影響は有意でないという結果が得られた。
## Estimate Std. Error z value Pr(>|z|) p.left p.rigth
## (Intercept) 0.98545083 0.266388102 3.6993050 2.161907e-04 0.670 0.330
## eigen -0.02182084 0.202649228 -0.1076779 9.142512e-01 0.528 0.472
## rank 0.06799049 0.009906833 6.8629891 6.743438e-12 1.000 0.000
## age -0.10673068 0.020844294 -5.1203790 3.049222e-07 0.000 1.000
## p.two.sides lower.ci uper.ci mean
## (Intercept) 0.660 0.49409368 1.27854434 0.8797652261
## eigen 0.944 -0.40437345 0.33759754 -0.0388205044
## rank 0.000 -0.01811588 0.02008254 0.0008329045
## age 0.000 -0.04153359 0.03513181 -0.00297682784.2.2.2 ネットワーク同士の関連の検討
Node permutationはネットワーク同士の関連を調べる際にも用いられることが多い。
4.2.2.2.1 ネットワーク間の相関の検定
4.2.2.2.1.1 Mantel検定
ネットワーク間の相関の検定方法として、よく知られているのがMantel検定(Mantel, 1967)である。Mantel検定は一般的に以下の手順に沿って行う(2つの隣接行列の相関を調べる場合)。
2つの隣接行列の対応する行列成分同士の相関係数を算出する。このとき、Pearsonの積率相関係数、Spearmanの順位相関係数、Kendallの順位相関係数のどれでもよい。
一方の隣接行列に対してnode permutationを行い、もう一方の隣接行列との相関係数を1と同様に算出する。
2を少なくとも1000回行う。
実際の相関係数がnode permutationによって算出された相関係数の何%より大きい/小さいかをP値とし、相関係数の有意性を判断する。
Rでは、veganパッケージのmantel関数などでMantel検定を行うことができる。ただし、今のところmantel関数は方向性のない隣接行列にしか適用できない点に注意。
ここでは、第2章で算出した方向性のない毛づくろい頻度ネットワークgroom_mat_b(表2.5)と出席データを基にしたSRIマトリックスpresence_mat(表2.7)の相関を求めてみる。
まず、groom_mat_bにいるKuriとTamという個体はpresence_matにはいないので、それらの個体を除く。また、両方の隣接行列の名前順をアルファベット順に合わせる。
## KuriとTamを除く
groom_mat_b2 <- groom_mat_b[-c(10,15),-c(10,15)]
## アルファベット順に並び替える
presence_mat <- presence_mat[sort(colnames(presence_mat)), sort(rownames(presence_mat))]それでは、Mantel検定を行う。ここでは、いずれの隣接行列の値も正規分布からは外れているので、Spearmanの相関係数で検定を行う。結果は、P値(Significance)が0.05以上ということで有意ではない。
library(vegan)
mantel(groom_mat_b2, presence_mat,
## 相関係数の種類。"pearson"または"kendall"でもよい
method = "spearman",
## node permutationの回数
permutations = 1000)##
## Mantel statistic based on Spearman's rank correlation rho
##
## Call:
## mantel(xdis = groom_mat_b2, ydis = presence_mat, method = "spearman", permutations = 1000)
##
## Mantel statistic r: 0.08256
## Significance: 0.22577
##
## Upper quantiles of permutations (null model):
## 90% 95% 97.5% 99%
## 0.137 0.184 0.210 0.253
## Permutation: free
## Number of permutations: 1000Mantel検定では、第3の要因(これも隣接行列の形で表す)の影響を取り除いたうえでの相関係数(= 偏相関係数)も算出することができる。ただし、マニュアルによるとPearsonの相関係数以外の値は信頼できないよう。
ここでは、順位差(rank_mat)の影響を統制したうえで、先ほどの2つの隣接行列の相関を調べる。まず、順位差を入れた隣接行列を作成する。
data.frame(ID = colnames(presence_mat),
rank = c(8,9,11,12,1,2,3,5,4,14,15,13,6,7,10)) -> rank
tidyr::crossing(ID1 = colnames(presence_mat),
ID2 = colnames(presence_mat)) %>%
left_join(rank, by = c("ID1" = "ID")) %>%
left_join(rank, by = c("ID2" = "ID")) %>%
mutate(rank_diff = abs(rank.x - rank.y)) %>%
select(ID1,ID2,rank_diff) %>%
mutate(rank_diff = as.numeric(rank_diff)) %>%
pivot_wider(names_from = ID2,
values_from = rank_diff) %>%
column_to_rownames(var = "ID1") %>%
as.matrix() -> rank_mat偏相関係数の検定は、veganパッケージのmantel.partial関数で行うことができる。結果は、順位を統制しても毛づくろいネットワークとSRIネットワークに有意な相関はない。
mantel.partial(groom_mat_b2, presence_mat,
## 統制する隣接行列
zdis = rank_mat,
## パーミュテーション回数
permutations = 1000)##
## Partial Mantel statistic based on Pearson's product-moment correlation
##
## Call:
## mantel.partial(xdis = groom_mat_b2, ydis = presence_mat, zdis = rank_mat, permutations = 1000)
##
## Mantel statistic r: -0.03687
## Significance: 0.71229
##
## Upper quantiles of permutations (null model):
## 90% 95% 97.5% 99%
## 0.0863 0.0998 0.1174 0.1387
## Permutation: free
## Number of permutations: 10004.2.2.2.1.2 Hemelrijkの行列相関検定
ヘメリック(Hemelrijk, 1990a; Hemelrijk, 1990b)は、霊長類において互恵性が存在するかを検討するために、Kendallの順位相関係数を発展させたKr検定を考案している。この方法もnode permutationを用いたもので、方向性のある隣接行列も扱うことができる。詳細はヘメリックの論文を参照されたし(Hemelrijk, 1990a; Hemelrijk, 1990b)。ANTsパッケージのstat.tauKr関数はこの方法に基づく行列相関検定を行ってくれる。
例えば、群れ内において毛づくろいの互恵性が成立しているか、つまり各ダイアッドが毛づくろいを交換しているかを調べたいとしよう。そのためには、方向性のある毛づくろい頻度隣接行列groom_mat(表2.3)とその転置行列(行と列を入れ替えた行列)の相関があるかを調べればよい。そうすれば、ある個体にたくさん毛づくろいをしているほど、その相手からも毛づくろいされているか、を調べることができる。転置行列はt()関数で求められる。
分析の結果は以下のようになる。pRとpLはランダムなネットワークの相関係数が実際の相関係数より大きい/小さい確率を表す。この結果から、両者の間には有意な相関があり、毛づくろいの互恵性が成り立っていることが示唆される。つまり、毛づくろいをたくさん行うほど、その個体から毛づくろいをされている。
stat.tauKr(X = groom_mat,
## 転置行列
Y = t(groom_mat),
## 対角成分は含まない
omitDiag = TRUE,
## node permutationの回数
nperm = 1000)## $tau
## [1] 0.7155429
##
## $pR
## [1] 0.000999001
##
## $pL
## [1] 1Kr検定では、第3の要因を統制した偏相関係数を検定することもできる。例えば、毛づくろいの互恵性が血縁度の影響を統制したうえでも成立するかを調べたいとする。
まず、各ダイアッドの血縁度をまとめた隣接行列を読み込み、行名と列名の順番をgroom_matに合わせる。
kin_mat <- read.csv("data/kin_demo.csv", row.names = 1) %>%
mutate(across(1:17, ~{as.double(.x)})) %>%
as.matrix()
kin_mat <- kin_mat[sort(colnames(groom_mat)),sort(rownames(groom_mat))]
diag(kin_mat) <- 0Kr検定の偏相関係数バージョンは以下のように行うことができる。Tauxyzが偏相関係数の値を表す。血縁度を統制したうえでも、毛づくろいの互恵性は成立していることがわかる。
stat.tauKr(X = groom_mat,
Y = t(groom_mat),
## 統制する要因の隣接行列
Z = kin_mat,
## 対角成分は含まない
omitDiag = TRUE,
## node permutationの回数
nperm = 1000)## WARNING: Error exit, tauk2. IFAULT = 12
## WARNING: Error exit, tauk2. IFAULT = 12## $Tauxy
## [1] 0.7155429
##
## $Tauxz
## [1] 0.6010751
##
## $Tauyz
## [1] 0.5194072
##
## $Tauxyz
## [1] 0.5906012
##
## $pR
## [1] 0.000999001
##
## $pL
## [1] 1同様の分析は、異なる行動から算出した2つの隣接行列に対しても適用できる。他の例については、 Hemelrijk (1990b) , Hemelrijk (1990a) , D. Croft et al. (2008) などを参照。
4.2.2.2.2 ネットワークデータを用いた回帰分析
ネットワーク相関は有用な方法だが、2つ以上の変数を統制したい場合には用いることができない。また、相関分析では様々な形式のデータ(0/1データ、割合データ)などを扱う際に問題が生じることもある。これらの問題点を解決してくれるのが、MRQAP検定(Dekker et al., 2007)と呼ばれる手法である。MRQAP検定は、簡単に言ってしまえばネットワークデータを用いた回帰分析である。Mantel検定などと同様に、2つ以上の隣接行列の対応する行列成分に対して回帰分析を施す。
例えば、第2章で算出したSRI隣接行列(表2.7)が、親密度(CSI)、血縁度、順位差と関連しているかを調べたいとする。MRQAPでは、通常のGLMやGLMMと同様に、こうした複数の隣接行列を用いた回帰分析を行うことができる(図4.10)。また、aninetパッケージのglmqap関数を用いれば、応答変数となる隣接行列の分布として様々なもの(e.g., 正規分布、ポワソン分布、二項分布など)を仮定することができるので、データ形式に合った適切な分析を行うこともできる。
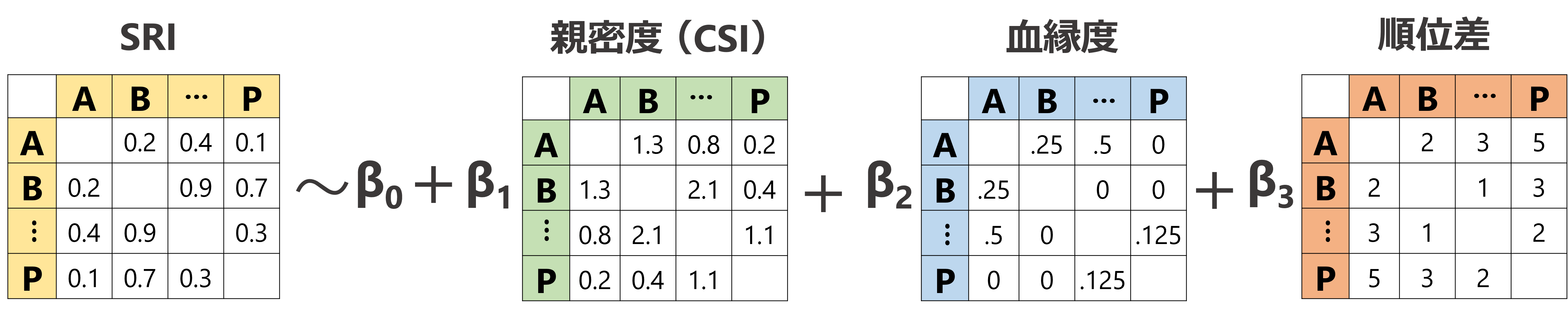
図4.10: MRQAP検定のイメージ図
MRQAP検定では、通常のnode permutationを発展させたdouble semi-partialing (DSP)法を用いて係数の有意性を判定する。この方法では、回帰分析をした際の残差に対してnode permutationを行うことでP値を算出する。少し複雑なので、詳しい説明は Dekker et al. (2007) や、 Borgatti et al. (2022) を参照。DSP法を用いれば、強い多重共線性がある場合でも、正確にP値を算出することができる。
それでは、実際に第2章で算出したSRIが、メス間の親密度(CSI)、血縁度、順位差の影響を受けるかを検討してみよう。ここでは、先ほども用いたメス同士の毛づくろい頻度groom_mat_b2と近接時間割合を用いてCSIを算出するとする。CSIは以下の式で算出される(Silk et al., 2006)。ただし、\(N\)はメス個体数である。
- \(G_{ij}\): メス\(i\)とメス\(j\)の毛づくろい時間割合
- \(P_{ij}\): メス\(i\)とメス\(j\)の近接時間割合
- \(\overline{G}: \frac{1}{N} \sum^{N}_{i=1}G_{ij}\)
- \(\overline{P}: \frac{1}{N} \sum^{N}_{i=1}P_{ij}\)
\[
CSI_{ij} = \frac{\left(\frac{G_{i}}{\overline{G}} +\frac{P_{i}}{\overline{P}}\right)}{2}
\]
まず、メス間の近接時間割合を記した隣接行列を読み込み、行と列をアルファベット順に並べ替える。
## 読み込み
prox_mat <- read.csv("data/prox_f.csv", row.names = 1) %>%
as.matrix()
## 並べ替え
prox_mat <- prox_mat[sort(rownames(groom_mat_b2)), sort(colnames(groom_mat_b2))]
diag(prox_mat) <- 0CSIは、aninetパッケージのdyadic_csi関数で以下のように簡単に求めることができる。
library(aninet)
list <- list(groom_mat_b2, prox_mat)
CSI_mat <- dyadic_csi(list)
## 列名と行名を追加
colnames(CSI_mat) <- colnames(prox_mat)
rownames(CSI_mat) <- rownames(prox_mat)| Aka | Ako | Hen | Hot | Kil | Kit | Koh | Kor | Kun | Mal | Mei | Mik | Ntr | Ten | Tot | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aka | 0.00 | 11.46 | 0.13 | 0.77 | 0.18 | 0.05 | 0.66 | 0.24 | 0.21 | 0.12 | 1.12 | 0.48 | 0.73 | 0.89 | 0.27 |
| Ako | 11.46 | 0.00 | 1.14 | 0.31 | 0.31 | 0.49 | 0.26 | 0.93 | 0.31 | 0.14 | 2.48 | 0.34 | 1.08 | 1.23 | 0.51 |
| Hen | 0.13 | 1.14 | 0.00 | 0.99 | 0.19 | 0.42 | 0.30 | 0.51 | 0.20 | 1.41 | 1.49 | 0.71 | 0.74 | 0.83 | 0.85 |
| Hot | 0.77 | 0.31 | 0.99 | 0.00 | 0.18 | 0.16 | 0.07 | 0.25 | 0.69 | 0.70 | 0.43 | 0.56 | 0.08 | 0.54 | 1.72 |
| Kil | 0.18 | 0.31 | 0.19 | 0.18 | 0.00 | 5.69 | 3.10 | 0.89 | 1.39 | 0.24 | 0.20 | 0.56 | 0.60 | 0.62 | 0.34 |
| Kit | 0.05 | 0.49 | 0.42 | 0.16 | 5.69 | 0.00 | 3.88 | 1.39 | 1.30 | 0.16 | 0.30 | 0.45 | 0.82 | 0.61 | 0.58 |
| Koh | 0.66 | 0.26 | 0.30 | 0.07 | 3.10 | 3.88 | 0.00 | 2.77 | 1.58 | 0.18 | 0.21 | 0.43 | 0.35 | 0.31 | 0.57 |
| Kor | 0.24 | 0.93 | 0.51 | 0.25 | 0.89 | 1.39 | 2.77 | 0.00 | 1.31 | 0.35 | 0.46 | 1.27 | 2.16 | 1.67 | 2.94 |
| Kun | 0.21 | 0.31 | 0.20 | 0.69 | 1.39 | 1.30 | 1.58 | 1.31 | 0.00 | 0.88 | 0.06 | 1.14 | 0.42 | 0.59 | 0.11 |
| Mal | 0.12 | 0.14 | 1.41 | 0.70 | 0.24 | 0.16 | 0.18 | 0.35 | 0.88 | 0.00 | 1.30 | 6.32 | 0.40 | 0.92 | 1.63 |
| Mei | 1.12 | 2.48 | 1.49 | 0.43 | 0.20 | 0.30 | 0.21 | 0.46 | 0.06 | 1.30 | 0.00 | 1.06 | 1.22 | 0.68 | 0.33 |
| Mik | 0.48 | 0.34 | 0.71 | 0.56 | 0.56 | 0.45 | 0.43 | 1.27 | 1.14 | 6.32 | 1.06 | 0.00 | 1.11 | 1.19 | 0.34 |
| Ntr | 0.73 | 1.08 | 0.74 | 0.08 | 0.60 | 0.82 | 0.35 | 2.16 | 0.42 | 0.40 | 1.22 | 1.11 | 0.00 | 2.43 | 1.06 |
| Ten | 0.89 | 1.23 | 0.83 | 0.54 | 0.62 | 0.61 | 0.31 | 1.67 | 0.59 | 0.92 | 0.68 | 1.19 | 2.43 | 0.00 | 1.25 |
| Tot | 0.27 | 0.51 | 0.85 | 1.72 | 0.34 | 0.58 | 0.57 | 2.94 | 0.11 | 1.63 | 0.33 | 0.34 | 1.06 | 1.25 | 0.00 |
順位差の隣接行列も読み込み、同様に列名と行名をアルファベット順にする。
## 読み込み
rank_mat <- read.csv("data/rank_demo.csv", row.names = 1) %>%
as.matrix()
## 並び替え
rank_mat <- rank_mat[sort(colnames(CSI_mat)), sort(rownames(CSI_mat))]
diag(rank_mat) <- 0先ほど読み込んだ血縁度の隣接行列から、SRI隣接行列に存在しない個体KurとTamを除く。
それでは、MRQAP検定に移ろう。SRIは0~1の間をとる割合データであるため、応答変数の分布は二項分布とする。分析には、aninetパッケージを用いる(Franks et al., 2021)。
二項分布を仮定した分析では、SRIを算出した際の分母が必要になる。get_denominator関数で算出できる。
denom <- get_denominator(## 第2章で使用したgroup by individual形式のデータ
presence %>% dplyr::select(-date),
## HWIを算出したなら"HWI"
index = "SRI",
## 隣接行列の形式で出力.ベクトル形式なら"vector"。
return = "matrix")
## アルファベット順に並び替え
denom <- denom[sort(rownames(CSI_mat)),sort(colnames(CSI_mat))]分析は以下の通り。
## 出力があまりに長くなってしまうので、すでに出した結果を読み込む
#r_qap <- glmqap(presence_mat ~ CSI_mat + rank_mat + kin_mat_b,
# ## 分母の隣接行列
# weights = denom,
# ## 分布は二項分布、ポワソン分布なら"poisson"、正規分布なら"gaussian"。
# family = "binomial",
# ## パーミュテーションの回数
# nperm = 1000,
# ## パーミュテーションの方法。通常はDSP法
# permutation = "DSP")
r_qap <- readRDS("output/r_qap.rds")結果は以下の通り。P値は、P(two-tailed)というところに書いてある。CSI、血縁度、順位差のいずれもSRIとは有意に関連していないという結果になった。
## GLMQAP with Doube-Semi-Partialling
##
## Formula: presence_mat ~ CSI_mat + rank_mat + kin_mat_b
## Family: binomial
## Weights: denom
## Offset: NULL
## Permutations: 1000
##
## Coefficients:
## Estimate Std. Error Z P(two-tailed)
## Intercept 1.3216348913 0.0614308474
## CSI_mat -0.0291975665 0.0257974756 -1.1317993673 0.8011988012
## rank_mat -0.0172087483 0.0080241535 -2.1446185470 0.7732267732
## kin_mat_b 0.0001895603 0.4175293743 0.0004540047 0.9790209790
##
## log-likelihood: -1277.55 AIC: 2563.1 BIC: 2573.716 4.2.3 Node permutationの欠点
以上でみたように、node permutationは2つ以上の変数の関連を調べるうえで強力な方法である。一方で、この方法は観察にバイアスがあるときや、観察場所/時間の影響があるとき5には、誤った結論を導いてしまう可能性が高くなる(Farine, 2017; Farine & Carter, 2022; Weiss et al., 2021)。
分析するモデルにこれらの要因(観察回数や行動圏の重複度合いなど)を限り取り入れることで、誤った結論を導いてしまう可能性を低減することはできるがWeiss et al. (2021)、すべての場合に対処できるわけではないようだ(Farine & Carter, 2022)。この問題を解決するうえでは、次節で説明する pre-network permutation が有効な手段だと考えられている(Farine, 2017; Farine & Carter, 2022; Farine & Whitehead, 2015)。一方で、pre-network permutation も相関分析や回帰分析を行う上で問題点を抱えていることがわかってきている(Farine & Carter, 2022; Puga‐Gonzalez et al., 2021; Weiss et al., 2021)。これについては、次節で詳述する。
References
例えば、順位の高い個体ほど、あるいはオスの個体ほど発見しやすい/行動が観察しやすい時には、そうした特徴による観察バイアスが生じることになる。また、個体Aと個体Bが一緒に観察される割合が高いとき、それはその2個体が互いに選好しているからではなく、単に観察場所や期間の影響(その場所から移動するのが難しい、たまたま同じ期間に出没することが多かった)があるからという場合がある。↩︎