4 統計的検定
4.1 なぜランダム化検定が必要か?
隣接行列(ネットワーク)内の数値(= 交渉頻度やSRIなどのassociation index)は互いに独立ではない(D. P. Croft et al., 2011; Farine, 2017; Farine & Whitehead, 2015)。これは、同じ個体が関連する交渉/association同士は、その個体に由来する何らかの傾向を含んでいるからである。例えば、図4.1のグラフにおいて、ノードAが(相手に依らず)そもそも他個体とよく交渉を行う個体だったとしよう。そうすると、ノードAに関連する交渉の頻度(= AとB, AとC, AとD, AとEの間の辺の重み)は全体的に高い傾向になると考えられる。このように、ノードAが関連するの辺の重みは独立ではない。これは、他のノードが関連する交渉についても同様に当てはまる。
このような非独立性はネットワークの中心性指標についてもいえる。例えば、図4.1のグラフの重みづけ中心性について考える。ノードAとCの重みづけ中心性をそれぞれ計算するとき、どちらの計算にもAとCをつなぐ辺の重み(3)が入ってくる(A:1+1+2+3; C: 2+2+3)。つまり、これらのノードの重みづけ中心性は互いに関連しあっている(= 独立ではない)。これは、辺で繋がっている全てのノード同士の重み付き中心性について言える。
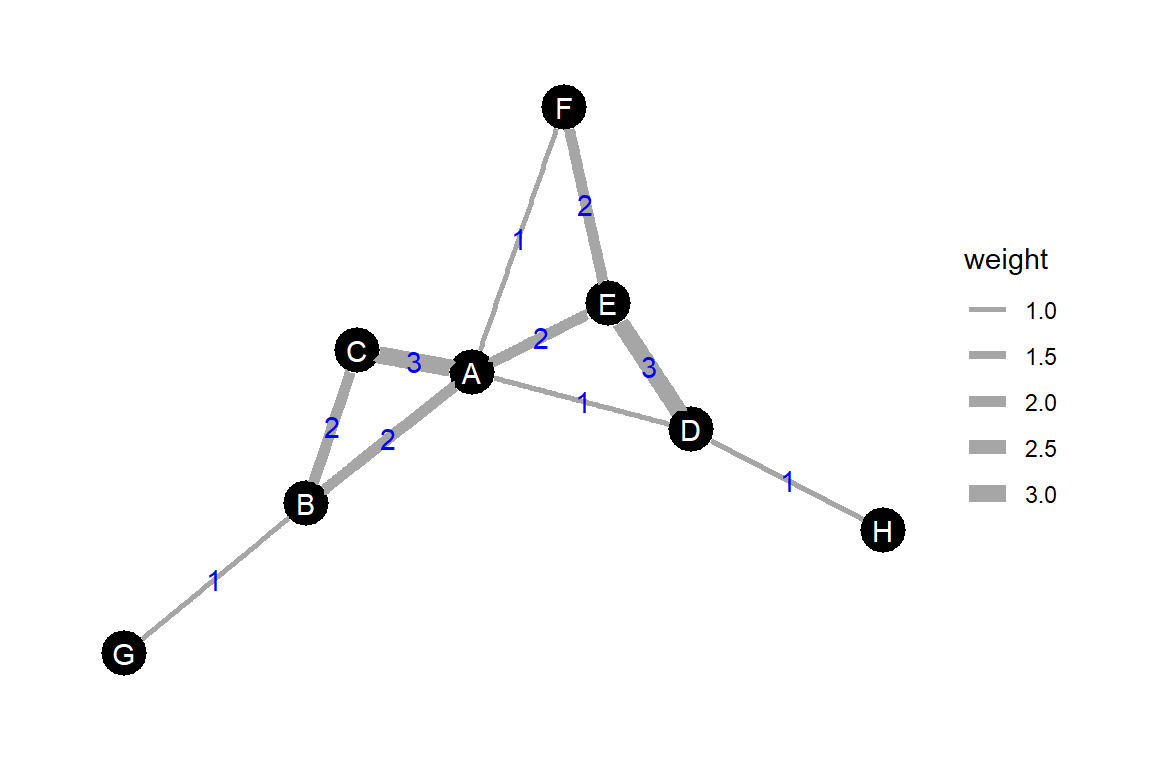
図4.1: ネットワークデータの非独立性の説明のためのグラフ
これは、統計的な分析を行おうとするときに大きな問題になる。なぜなら、ほとんどの統計分析(t検定、相関分析、GLMなどの回帰分析、…)ではデータが互いに独立していることが仮定されているからである(D. P. Croft et al., 2011)。そのため、ネットワークデータにそのままこのような分析を適用すると、誤った結果が得られる確率(= 第一種の過誤や第二種の過誤が生じる確率)が高くなってしまうのである。
この問題に対処するために最もよく用いられる方法がランダム化検定(randomization test)である(D. P. Croft et al., 2011; Farine, 2017; Farine & Whitehead, 2015)。ランダム化検定とは、「ランダムな」ネットワークを大量(少なくとも1000回以上)に生成した後、それらから得られた統計検定量(e.g., t検定量や回帰係数など)の分布を帰無分布4として、実際の統計検定量の有意性を判定する方法である。ここでの「ランダム」なネットワークは、帰無仮説が正しいときの個体間の交渉やassociationを表すものでなくてはならない。例えば、「毛づくろいネットワークにおける中心性と年齢に関連がある」という仮説を検証するのであれば、年齢にかかわらずランダムに毛づくろいが行われているネットワークをランダムネットワークとして生成する必要がある。
加えて、適切にランダム化検定を行うためには、検定の対象となる側面(e.g., 中心性指標と順位の関係、個体間の交渉頻度と性別・年齢の関係など)についてはランダム化する一方で、それ以外の側面(e.g., 各個体の観察回数、ノードと辺の数、ネットワークの構造など)については可能な限り一定になるようにランダムネットワークを生成することが重要である。この点を考慮するため、ネットワーク分析では実データをシャッフルすることでランダムなネットワークを生成するパーミュテーション検定(permutation test)がよく用いられる。
ネットワークデータへのパーミュテーション検定は、通常以下の5つのステップで行われる(Farine, 2017 を改変)。
- 観察データから社会ネットワークを生成する。
- 1で作成した社会ネットワークに対して統計分析を行い、統計検定量(e.g., t検定ならt統計量、GLMなどの回帰分析なら回帰係数)を算出する。
- 観察データをシャッフルし、ランダムなネットワークをたくさん作る(少なくとも1000個)。
- それぞれのランダムネットワークに対して、2と同じ統計分析を行い、統計検定量を算出する。
- 2の統計検定量を4の統計検定量の分布と比較する。両者に大きな乖離があれば、仮説が正しいと結論付ける。例えば有意水準が5%のときには、2の統計検定量が4の統計検定量の95%より大き/小さければ、帰無仮説を棄却することになる。
パーミュテーション検定は、どの段階のデータをシャッフルするかによって大きく2つに分けられる。以下では、それぞれについて詳しくみていく。より詳しい解説は D. P. Croft et al. (2011)、 Farine & Whitehead (2015)、 Farine (2017) を参照。
- Network permutation: 既に作られたネットワーク上のノードや辺をシャッフルする。
- Pre-network permutation (またはData stream permutation): ネットワークを作る前に、交渉やassociationの生データをシャッフルする。