2 構造的因果モデルと因果ダイアグラムの基礎
2.1 確率と統計の基礎
まずは、確率と統計についての基礎知識の復習から行う。
変数: 複数の値を取りうる特性(例: 被験者の年齢、性別、採食時間割合、…)。以下、大文字のアルファベットで表す。
変数\(X\)が値\(x\)になる確率を\(P(X=x)\)と表す。
例: 性別を変数\(X\)とするとき、オスである確率は\(P(X = オス)\)と書ける。同時確率: \(X = x\) かつ \(Y = y\)である確率を、\(P(X=x,Y=y)\)と表す。
条件付き確率: \(X =x\)であるときに\(Y=y\)となる確率を\(P(Y=y|X=x)\)と書き、このような確率を条件付き確率という。なお、\(P(X=x, Y=y) = P(Y=y|X=x)\times P(X=x)\)と表せる。
例: オスの採食時間割合(\(Y\))が20%より多い確率は、\(P(Y > 20|X = オス)\)。確率分布: ある変数\(X\)がとりうる全ての値について、それが起きる確率の分布を示したものである。なお、変数\(X\)がある確率分布\(P(X=x)\)に従うとき、\(X \sim P(x)\)と書く。
確率分布の例
離散変数の場合 (例. ある湖で1時間にとれる魚の数\(X\)の確率分布2)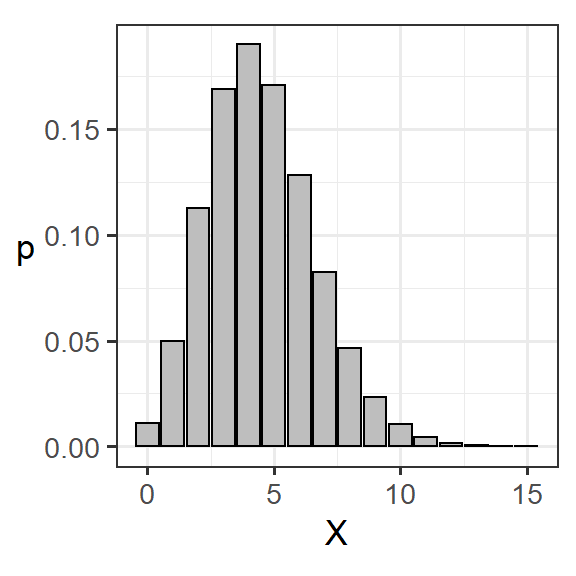
図2.1: 離散変数の確率分布
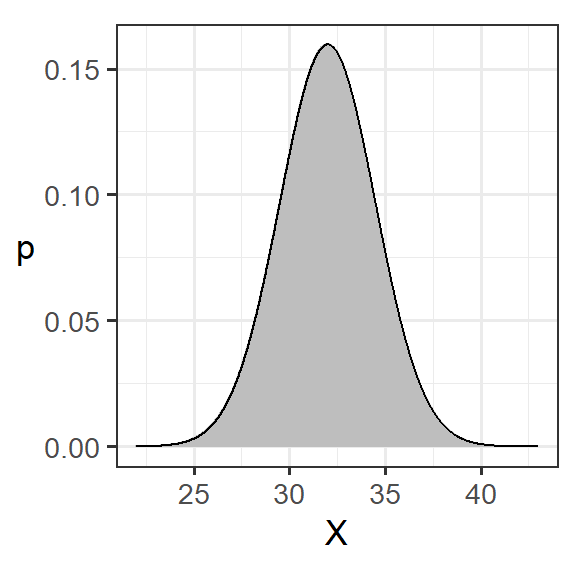
図2.2: 連続変数の確率分布
2.2 構造的因果モデル(SCM)
変数間の因果関係を記述するためには、データセットにある変数間の因果関係についての仮定を正式に記述する必要がある。そのために、構造的因果モデル(SCM: Structural Causal Model)を導入する。SCMは、以下の3つによって記述される。
- \(V\): その変動理由がモデル内で記述される変数(内生変数)の集合
- \(U\): その変動理由がモデル内で記述されない変数(外生変数)の集合
- \(F\): モデル内の他の変数によって内生変数の値を決定する関数の集合
外生変数は他の変数によって記述できない(=他の変数の子孫ではない)。
一方で、内生変数は少なくとも1つの外生変数を含む関数を用いて記述される(=少なくとも1つの外生変数の子孫である)。すなわち、すべての外生変数の値が分かれば、関数\(F\)により全ての内生変数の値が正確に決定される。
例: 教育レベル(\(X\))と職務経験(\(Y\))、給料(\(Z\))の関係
以下の関数\(f_Z\)に基づき、\(Z\)が\(X\)と\(Y\)によって決定されるとする。
\(U = \lbrace X, Y \rbrace, V = \lbrace Z \rbrace, F = \lbrace f_Z \rbrace\)
\[
\begin{aligned}
f_Z: Z &= 2X + 3Y
\end{aligned}
\]
因果の定義(Pearl et al. 2016)
SCM内で\(Y\)の値を決定する関数に\(X\)が使われるとき、\(X\)は\(Y\)の直接原因であるという。\(X\)が\(Y\)の直接原因であるか、\(Y\)の原因の直接原因であるとき、\(X\)は\(Y\)の原因であるという。上の例では、\(X\)と\(Y\)は\(Z\)の直接原因である。
ひとことメモ
因果関係の定義には様々な流儀があり、ここではPearl et al. (2016)の定義を紹介した。
前述の定義とほとんど同じであるが、例えば林・黒木(2016)は以下のように定義している。
「要因\(X\)を人為的に変化させた(介入した)とき、要因\(Y\)も変化する」とき「要因\(X \rightarrow Y\)の因果関係がある」と呼ぶ
2.3 因果ダイアグラムの概要
因果ダイアグラムとは、図1.1のように丸(記号は何でもよいが)と矢印を用いて変数間の因果構造を表したものである。矢印は因果関係を表し、それぞれのSCMには対応する因果ダイアグラムが必ず存在する。因果ダイアグラムを活用することで、定量的なデータに依ることなくモデルの中に存在する変数の関係を表現することができるので、因果推論を行う上で非常に重要なツールである。
先ほどの例を因果ダイアグラムで表すと以下のようになる。
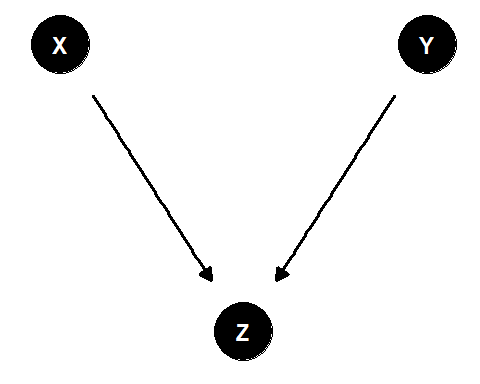
図2.3: 因果ダイアグラムの例
2.4 因果ダイアグラムの描き方
ここでは、Rでの因果ダイアグラムの描き方を解説する。
まずはノード(点)の名前と位置(x,y座標)を記したデータフレーム(あるいはtibble)を作成する。
dag1 <- tibble(name = c("A","B","C","D"),
x = c(1, 2, 3, 2),
y = c(2, 2, 2, 1))その後、dagify()でノード間の関係を記述する。
y ~ xはy <- xを表す。
x1 ~~ x2はx1 <-> x2を表す。
dagified_dag1 <- dagify(A ~ B,
C ~ B,
D ~ A + C,
## 暴露変数の指定ができる
exposure = "C",
## 結果変数の指定ができる
outcome = "D",
coords = dag1)グラフの描画に必要な情報が書き込まれるよう。
dagified_dag1## dag {
## A [pos="1.000,2.000"]
## B [pos="2.000,2.000"]
## C [exposure,pos="3.000,2.000"]
## D [outcome,pos="2.000,1.000"]
## A -> D
## B -> A
## B -> C
## C -> D
## }tidy_dagitty()でデータフレームの形で出力もできる。
tidy_dagitty(dagified_dag1)## # A DAG with 4 nodes and 4 edges
## #
## # Exposure: C
## # Outcome: D
## #
## # A tibble: 5 × 8
## name x y direction to xend yend circular
## <chr> <int> <int> <fct> <chr> <int> <int> <lgl>
## 1 A 1 2 -> D 2 1 FALSE
## 2 B 2 2 -> A 1 2 FALSE
## 3 B 2 2 -> C 3 2 FALSE
## 4 C 3 2 -> D 2 1 FALSE
## 5 D 2 1 <NA> <NA> NA NA FALSE最後に、ggplot()を用いてダイアグラムを描画する。
ggdagパッケージに含まれる関数も使用する。
ggplot(dagified_dag1,
aes(x = x, y=y, xend = xend, yend = yend))+
## ノード、文字、エッジの設定。Dのみ色を変える
geom_dag_point(aes(color = name == "D"),
alpha = 1/2, size = 10.5, show.legend = F)+
geom_dag_text(color = "black")+
geom_dag_edges()+
scale_color_manual(values = c("steelblue", "orange"))+
## 座標を消す
scale_x_continuous(NULL, breaks = NULL, expand = c(.1, .1)) +
scale_y_continuous(NULL, breaks = NULL, expand = c(.1, .1)) +
theme_minimal() +
theme(panel.grid = element_blank())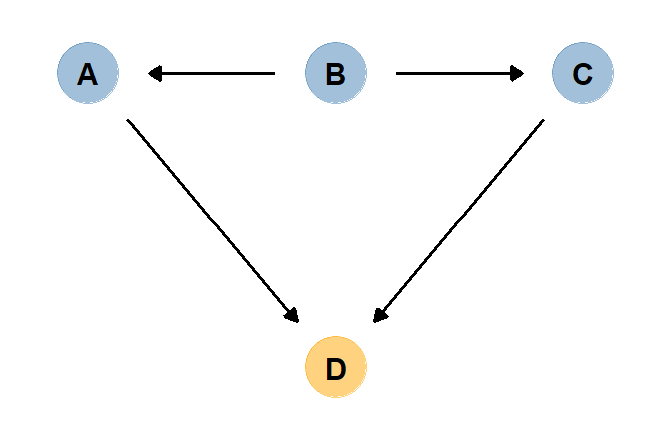
図2.4: 作成した因果ダイアグラム
特にこだわりがなければ、ggdag()で容易に描ける。
theme_dag()で最小限のテーマ(目盛や背景を削除)にしてくれる。
ggdag(dagified_dag1, node_size =10, text_size = 3)+
theme_dag()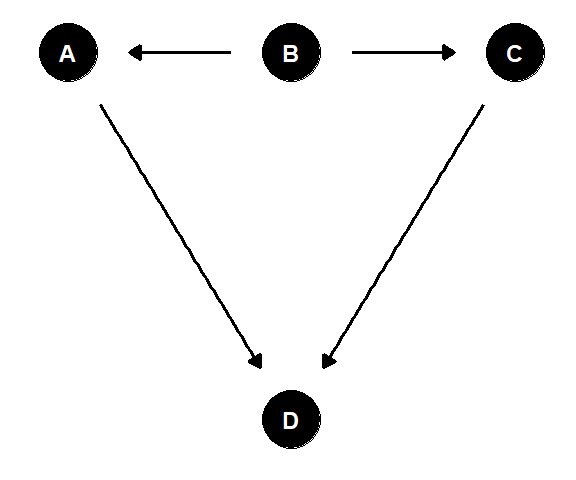
図2.5: ggdag()で描いた因果ダイアグラム
2.5 因果ダイアグラムの基礎
有向辺(方向のあるエッジ)の始点を親、終点を子と呼ぶ。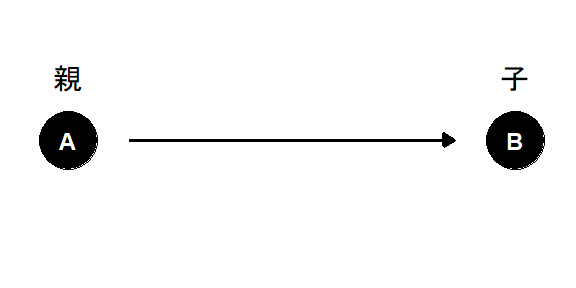
図2.6: ノードの親子
また、2つ以上のノードがあり、2つのノードをつなぐ道を矢印を伝ってたどることができるとき、つまり2つの有向辺が共に入ってくるノードや、2つの有向辺が共に出ていくノードがない場合(下図のようなとき)、これを有向道と呼ぶ。
有向道上の最初のノードは、道上のすべてのノードの祖先である(下図で、AはCの祖先、CはAの子孫(=孫)である)。
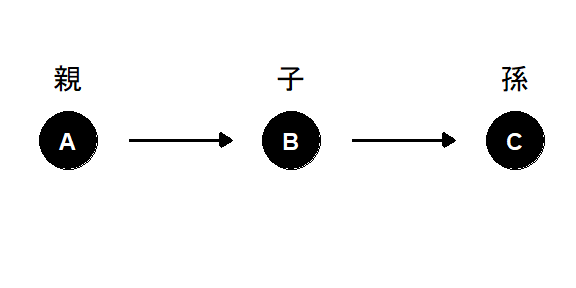
図2.7: ノードの親・子・孫
Rでは、dagittyパッケージでこれを求められる。
図2.4の因果ダイアグラムを用いて求めてみる。
親
## 親
parents(dagified_dag1,"D")## [1] "A" "C"## 子
children(dagified_dag1, "B")## [1] "A" "C"## 祖先
ancestors(dagified_dag1, "D")## [1] "D" "C" "B" "A"## 子孫
descendants(dagified_dag1, "B")## [1] "B" "C" "D" "A"また、特定の2つのノード間の有向道は以下のように求められる。
図2.4の因果ダイアグラムにおける\(B\)と\(D\)の間の有向道を調べると以下のようになる。
paths(dagified_dag1, "B", "D", directed = T)$path## [1] "B -> A -> D" "B -> C -> D"なお、矢印の向きにかかわらず、2つのノードAとBがエッジ(辺)によって繋がっているとき、それをAとBをつなぐ道という。
path()でdirected = Fとすると、有向道を含む全ての道を調べられる(この例では有向道しかないが…)。
paths(dagified_dag1, "B", "D", directed = F)$path## [1] "B -> A -> D" "B -> C -> D"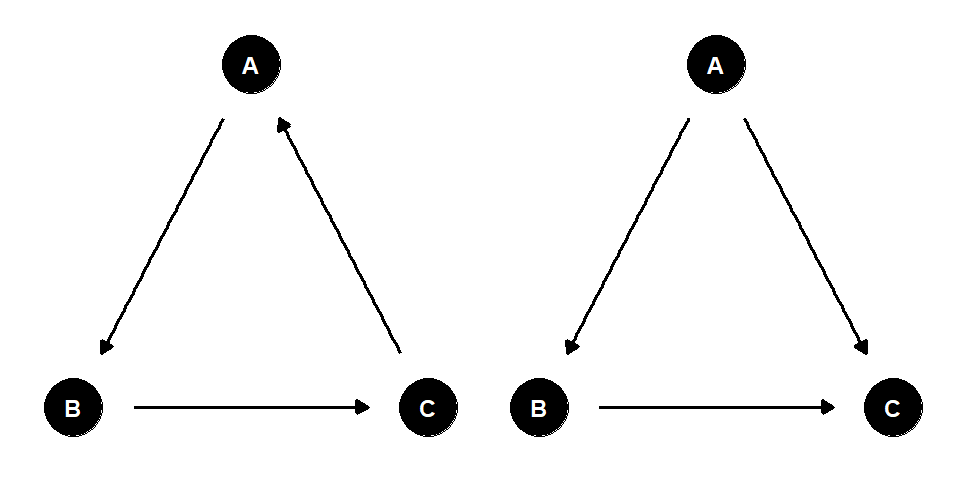
図2.8: 巡回的なグラフと非巡回的なグラフの例
2.6 独立と従属
2つの変数\(X\)と\(Y\)は、以下が成り立つときにそれぞれがとりうる全ての値\(x\)と\(y\)について独立という。
\[
P(X = x|Y = y) = P(X = x)
\]
すなわち、\(X\)と\(Y\)が独立のとき、変数\(Y\)の値がなんであろうと、\(P(X = x)\)の値は変わらない(= 相関がない)。独立は記号を用いて以下のように表せる。
\[
X \mathop{\perp\!\!\!\!\perp} Y
\]
また、確率変数\(Z\)の任意の値が与えられたときに\(X\)と\(Y\)が全ての\(x\)、\(y\)について独立のとき、\(X\)と\(Y\)は\(Z\)の下で条件付き独立であるといい、以下のようにあらわす。
\[
X \mathop{\perp\!\!\!\!\perp} Y|Z
\]
因果ダイアグラム上で独立または条件付き独立であるノードは、impliedConditionalIndependencies()を用いて以下のように求められる(例. 図2.4について)。
impliedConditionalIndependencies(dagified_dag1)## A _||_ C | B
## B _||_ D | A, Cなお、独立でない2変数は従属であるという。
ひとことメモ
実際の分析では、例えば以下のような場合に\(Z\)について条件付けしたことになる。
- ある\(Z\)の値のデータのみを抽出して分析する
- 偏相関係数の計算: \(Z\)の影響を排除して他の2変数相関係数を算出する
- 回帰分析: 説明変数に\(Z\)を加えて回帰分析を行う