3 因果ダイアグラムの因果推論への応用
この章では、因果ダイアグラムを因果推論へ応用する方法を学ぶ。
具体的には、以下の手順によって仮定した因果モデル(SCM)が正しいものか検証し、変数間の因果関係を探索することになる。
- あるSCM(とそれに対応する因果ダイアグラム)が正しいと仮定したとき、変数間の独立/従属関係がどのようになるかを調べる(3.1, 3.2)
- 実際のデータにおける独立/従属関係が、仮定した因果ダイアグラムから想定される独立/従属関係と一致するか確認することで、SCMで仮定した因果関係が正しいかを検証し、必要な場合は修正する(3.3)
3.1 因果ダイアグラムの基本3パターン
まず、因果ダイアグラムに現れる基本3パターンをまとめる。実際の因果ダイアグラムはより複雑だが、基本的にはどのようなダイアグラムもこの3パターンの因果構造の組み合わせで表せる。
本節ではそれぞれのパターンで、どのようなときに因果ダイアグラムに含まれる2変数が独立/従属になるかを学ぶ。これによって以下のことが可能になる。
- 相関(あるいは従属)\(\neq\)因果になるのがどのようなときなのかを理解できるようになる
- 最終的に、いかなる因果ダイアグラムにおいても、変数間の独立/従属関係が分かるようになる
3.1.1 連鎖経路(chain)
3.1.1.1 概要
図3.1のように3つのノードと2つのエッジがあり、中央の変数に1つのノードが入ってきて、また別のノードがそこから出ていく構成を連鎖経路(chain)と呼ぶ。
- \(X\)と\(Y\)は\(Z\)の原因である
- \(Y\)を\(X \rightarrow Z\)の因果関係における中間変数(あるいは媒介因子)という
dag4 <- tibble(name = c("X","Y","Z"),
x = c(1.5, 2, 2.5),
y = c(2.5, 2, 1.5))
dagified_chain <- dagify(Y ~ X,
Z ~ Y,
coords = dag4)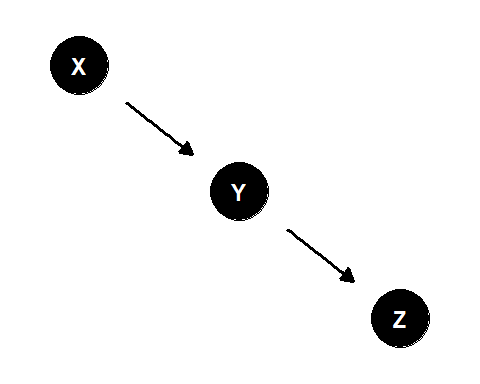
図3.1: 連鎖経路の例
連鎖経路では以下が成り立つ。
- \(X\)と\(Y\)、\(Y\)と\(Z\)、\(X\)と\(Z\)は特異な例を除けばそれぞれ従属である4
- \(X\)と\(Z\)は、\(Y\)の下で条件付き独立
2は、\(Y\)で条件づけると、因果関係がある\(X\)と\(Z\)の相関が消えてしまうことを示している。
2はRでも確かめられる()。
impliedConditionalIndependencies(dagified_chain)## X _||_ Z | Y3.1.1.2 連鎖経路の例
2は以下のような例でも確かめられる。
\(X\)、\(Y\)、\(Z\)の間に以下のような関係(SCM)が成り立つとする。
ただし、\(U_x\)、\(U_y\)、\(U_z\)は平均0で標準偏差1の正規分布に従い、互いに独立とする(以後同様)。
\[ \begin{aligned} X &= U_x\\ Y &= \frac{4}{5}X + U_y\\ Z &= \frac{2}{3}Y + U_z\\ \end{aligned} \]
上記のSCMは以下のようにも書き換えられる。
\(X \sim Normal(0,1)\)は\(X\)が平均0,標準偏差1の正規分布に従うことを表す。
ただし、\(i = 1, 2, ...,N\)である。
\[
\begin{aligned}
x_{i} &\sim Normal(0,1) \\
y_{i} &\sim Normal(\frac{4}{5}x_{i},1) \\
z_{i} &\sim Normal(\frac{2}{3}y_{i},1) \\
\end{aligned}
\]
実際にデータを生成して分析してみる。
N <- 10000
Ux <- rnorm( N ); Uy <- rnorm( N ); Uz <- rnorm( N )
X <- Ux
Y <- 4/5*X + Uy
Z <- 2/3*Y + Uz
d <- data.frame(X=X,Y=Y,Z=Z)\(X\)、\(Y\)、\(Z\)の関係を見ると、互いに有意に相関している(\(X\),\(Y\),\(Z\)は互いに従属)。
ggpairs(d)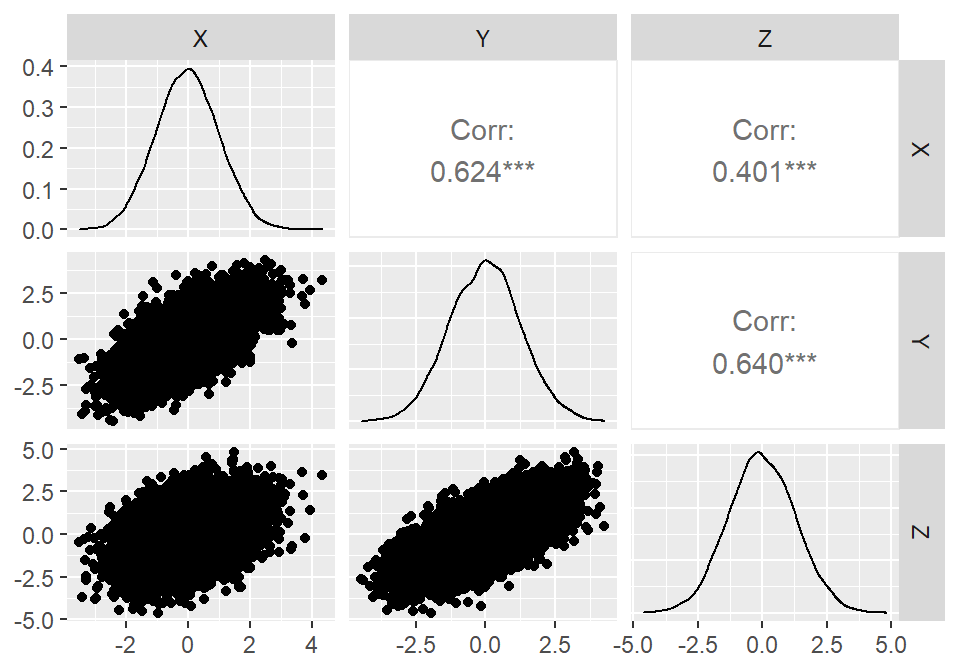
図3.2: 連鎖経路におけるX, Y, Zの間の関係
回帰分析(\(Z \sim X\))をすると、\(X\)と\(Z\)は有意に関連している(\(X\)と\(Z\)は従属)。
model_parameters(lm(Z~X,d)) %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | -0.007 | 0.012 | 0.558 |
| X | 0.520 | 0.012 | 0.000 |
しかし、説明変数に\(Y\)も加えると(=\(Y\)で条件づけると)、\(X\)の係数はほぼ0になり、因果関係がある\(X\)と\(Z\)の関連は消失してしまう。このことからも、\(X\)と\(Z\)は、\(Y\)の下で条件付き独立であることが分かる。
▶ \(Y\)の値が分かれば、\(Z\)を予測するうえで\(X\)の値は関係なくなるから(\(X\)は\(Y\)を通してしか\(Z\)に影響を与えていないので)
model_parameters(lm(Z~X+Y,d)) %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | -0.008 | 0.010 | 0.451 |
| X | 0.004 | 0.013 | 0.780 |
| Y | 0.655 | 0.010 | 0.000 |
なお、XとYの間の有向道が1つだけあり、それが連鎖経路であるとき、\(X\)と\(Y\)はその間のいずれの変数(1つでなくともよい)の下でも条件付き独立である。すなわち、下図で\(X\)と\(W\)は\(Y\)と\(Z\)いずれでの下でも条件付き独立になる。
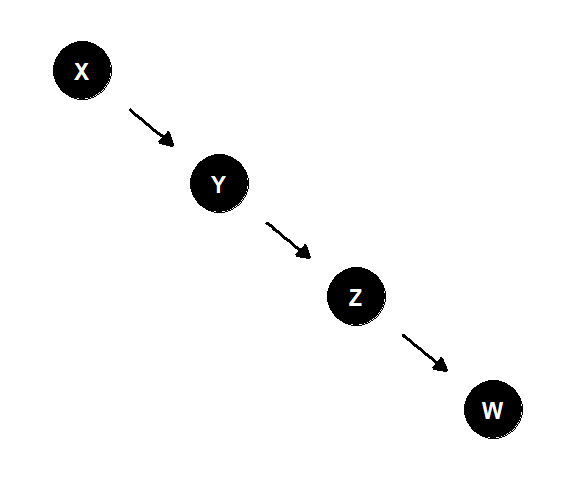
図3.3: 連鎖経路の例2
3.1.2 分岐経路(fork)
3.1.2.1 概要
図3.4のように、2つの変数に共通の変数が影響を与えているような構成を分岐経路(fork)と呼ぶ。またこのとき、\(X\)を交絡因子(変数)と呼ぶ。
dag5 <- tibble(name = c("X","Y","Z"),
x = c(2, 1, 3),
y = c(2, 1, 1))
dagify(Y ~ X,
Z ~ X,
coords = dag5) -> dagified_fork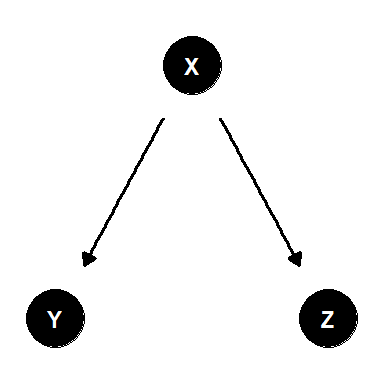
図3.4: 分岐経路の例
分岐経路では以下が成り立つ。
- \(X\)と\(Y\)、\(X\)と\(Z\)、\(Y\)と\(Z\)は特異な例を除けばそれぞれ従属
- \(Y\)と\(Z\)は\(X\)の下で条件付き独立
1は、交絡因子によって因果関係にない\(Y\)と\(Z\)の間に相関が生じてしまうことを示している。
2は、この相関は\(X\)で条件づけることによって消失することを示す。
これはRでも確かめられる。
impliedConditionalIndependencies(dagified_fork)## Y _||_ Z | X3.1.2.2 分岐経路の例
2を直観的に確かめるため、以下の例を考える。
\(X\)、\(Y\)、\(Z\)の間に以下のような関係(SCM)が成り立つと、\(X\)、\(Y\)、\(Z\)の関係は分岐経路で表せる。
- \(X\)(=気温)が\(Y\)(= アイスクリームの売上)と\(Z\)(= プール来場者数)に影響
- \(Y\)と\(Z\)は互いに影響しない
\[ \begin{aligned} X &= U_x\\ Y &= \frac{5}{2}X + U_y\\ Z &= \frac{2}{3}X + U_z\\ \end{aligned} \]
上記のSCMは以下のようにも書ける。
ただし、\(i = 1,2,...N\)。
\[
\begin{aligned}
x_{i} &\sim Normal(0,1) \\
y_{i} &\sim Normal(\frac{5}{2}x_{i},1) \\
z_{i} &\sim Normal(\frac{2}{3}x_{i},1) \\
\end{aligned}
\]
SCMをもとに実際にデータを生成してみる。
N <- 10000
Ux <- rnorm( N ); Uy <- rnorm( N ); Uz <- rnorm( N )
X <- Ux
Y <- 5/2*X + Uy
Z <- 2/3*X + Uz
d <- data.frame(X=X,Y=Y,Z=Z)\(X\)、\(Y\)、\(Z\)の関係を見ると、互いに有意に強く相関している(=\(X\),\(Y\),\(Z\)は互いに従属している)。
ggpairs(d)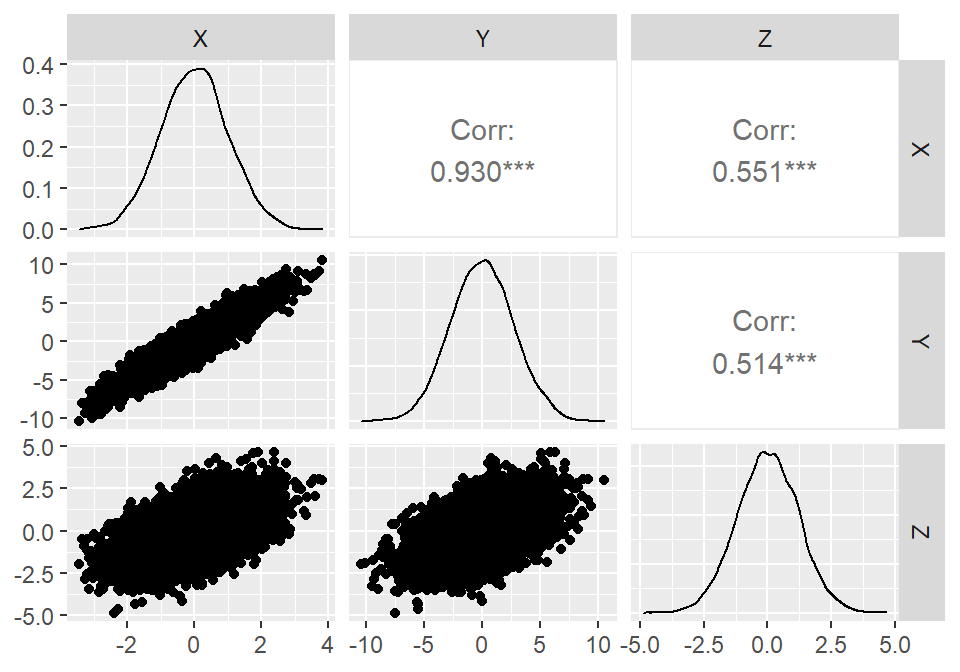
図3.5: 分岐経路におけるX, Y, Zの間の関係
回帰分析(\(Z \sim Y\))をすると、\(Y\)と\(Z\)は有意に関連している(\(Y\)と\(Z\)は従属)。
model_parameters(lm(Z~Y,d)) %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | 0.006 | 0.010 | 0.567 |
| Y | 0.228 | 0.004 | 0.000 |
しかし、説明変数に\(X\)も加えると(=\(X\)で条件づけると)、\(Y\)の係数はほぼ0になり、\(Y\)と\(Z\)の関連は消失する(=\(Y\)と\(Z\)は\(X\)の下で条件付き独立)。すなわち、交絡が解消された。
model_parameters(lm(Z~X+Y,d)) %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | 0.006 | 0.010 | 0.550 |
| X | 0.642 | 0.027 | 0.000 |
| Y | 0.006 | 0.010 | 0.535 |
3.1.3 合流点(collider)
3.1.3.1 概要
図3.6のようにあるノードに他の2つのノードからエッジが入ってきている構成を合流点(collider)と呼ぶ。
dag5 <- tibble(name = c("X","Z","Y"),
x = c(1, 2, 3),
y = c(2, 1, 2))
dagify(Z ~ X,
Z ~ Y,
coords = dag5) -> dagified_collider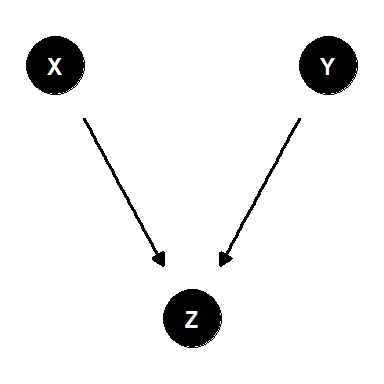
図3.6: 合流点の例
合流点では以下が成り立つ。
- \(X\)と\(Z\)、\(Y\)と\(Z\)は特異な例を除けばそれぞれ従属
- \(X\)と\(Y\)は独立
- \(X\)と\(Y\)は\(Z\)の下で条件付き従属
1は自明であり、2もRで確かめられる。
impliedConditionalIndependencies(dagified_collider)## X _||_ Y3.1.3.2 合流点の例1
1と2は直観的に理解できるが、3が成り立つのはなぜだろうか?
以下の例を考える。
ある大学の入学試験で以下のように合否を判定するとする
- 音楽試験の点数(\(X\))と学力試験の点数(\(Y\))の合計点で合否(\(Z\)、\(X+Y > 115\)なら合格)を判定
- \(X\)と\(Y\)には全く関連がない
- \(U_X\)と\(U_y\)はそれぞれ平均50、標準偏差10の正規分布に従う
\[ \begin{aligned} X &= U_x\\ Y &= U_y\\ Z &= \left\{ \begin{array}{ll} 1(合格) & (X + Y > 115)\\ 0(不合格) & (X + Y < 115) \end{array} \right. \end{aligned} \]
上記のSCMは以下のように書き換えられる。
ただし、\(i = 1,2,...N\)。
\[
\begin{aligned}
x_{i} &\sim Normal(50,10) \\
y_{i} &\sim Normal(50,10) \\
z &= \left\{
\begin{array}{ll}
1(合格) & (x_{i} + y_{i} > 115)\\
0(不合格) & (x_{i} + y_{i} < 115)
\end{array}
\right.
\end{aligned}
\]
実際にこれに基づいてデータを生成して分布をみてみると、1と2が確かめられる。
N <- 500
Ux <- rnorm(N, mean = 50, sd = 10); Uy <- rnorm(N, mean = 50, sd = 10); Uz <- rnorm( N )
X <- Ux
Y <- Uy
Z <- vector()
for(i in 1:500){
if (X[i] + Y[i] > 115){
Z[i] <- "1"
}else{
Z[i] <- "0"
}
}
d <- data.frame(X=X,Y=Y,Z=Z)- 合格者(\(Z=1\))の方が不合格者(\(Z=0\))より、\(X\)と\(Y\)がそれぞれ大きい(= \(X\)と\(Z\)、\(Y\)と\(Z\)は従属)
- \(X\)と\(Y\)には相関がない(= 独立)。
ggpairs(d)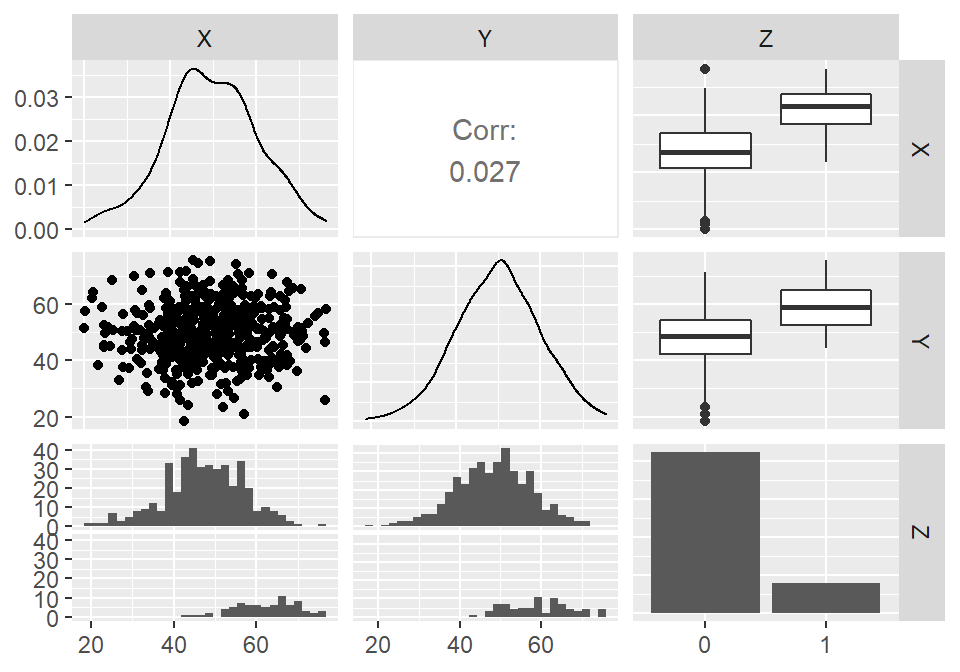
図3.7: 合流点を含む経路におけるX, Y, Zの間の関係
ここで、\(Z\)で条件付けるとどうなるだろうか。例えば、合格者(\(Z=1\))のデータのみを抽出する。
青い直線は合格者のみのデータを抽出したときの回帰直線である。このとき、因果関係にない\(X\)と\(Y\)の間に相関が生じていることが分かる(= \(X\)と\(Y\)は\(Z\)の下で条件付き従属)。これを合流点バイアスという。
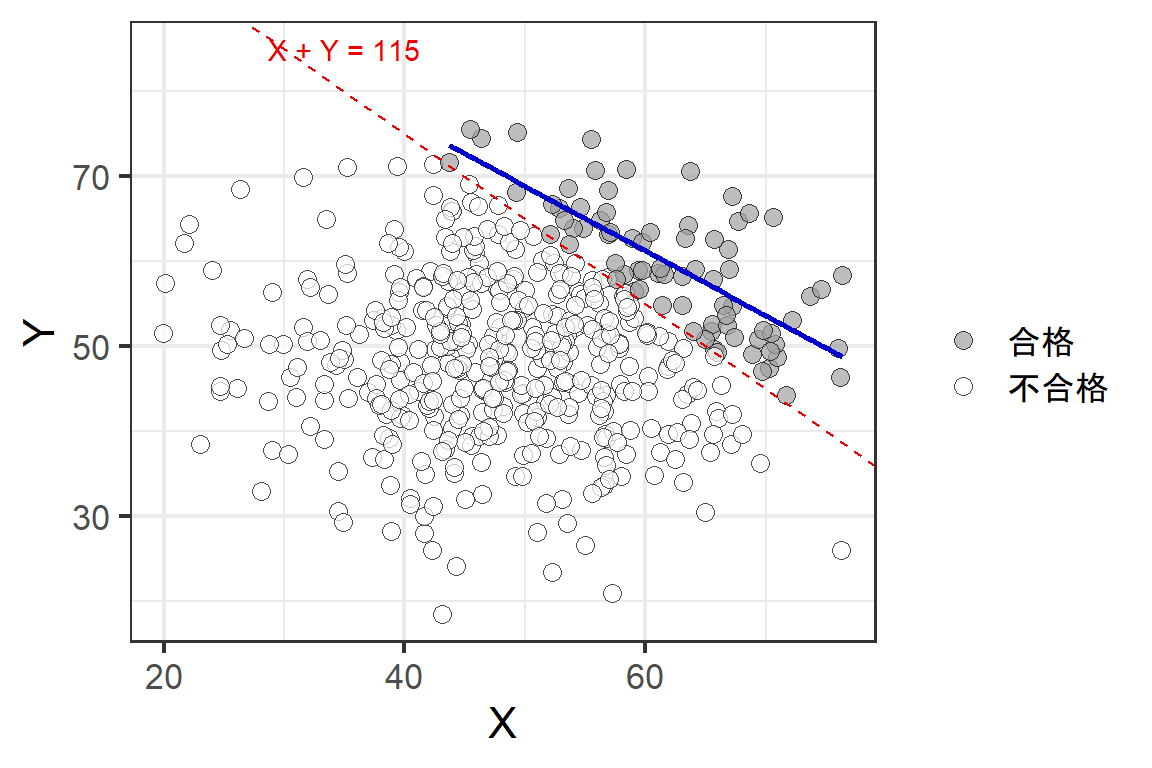
図3.8: 合流点バイアスの例
これは偏相関係数を算出することでも確かめられる。
\(Z\)を統制した場合の\(X\)と\(Y\)の偏相関係数を調べると、有意な相関が現れる(= \(X\)と\(Y\)は\(Z\)の下で条件付き従属)。
pcor.test(d$X,d$Y,d$Z %>% as.numeric())## estimate p.value statistic n gp Method
## 1 -0.2315841 1.681337e-07 -5.307092 500 1 pearson3.1.3.3 合流点の例2
なお、合流点だけでなく、合流点の子孫のいずれを条件付けした場合でも、独立した変数同士が従属になることがある。以下の例を考える。
交尾期において、各観察日にニホンザルの群れに訪れる群れ外オスの数(\(Z\))は、その日の発情メスの数(\(X\))と気温(\(Y\))によって決まるとする。また、メスがオスから攻撃される頻度(\(W\))は、その日に群れを訪れた群れ外オスの数(\(Z\))に依存するとする。
以下のSCMを考える。
\[ \begin{aligned} x_{i} &\sim Poisson(3.5)\\ y_{i} &\sim Normal(10,1.5)\\ z_{i} &\sim Poisson(0.8x_{i}+0.75y_{i}-2)\\ w &\sim Normal(0.4z_{i} + 1.2, 0.5) \end{aligned} \]
SCMを因果ダイアグラムで表すと図3.9のようになる。
dag6 <- tibble(name = c("X","Z","Y","W"),
x = c(1, 2, 3,2),
y = c(2, 1.5, 2,1))
dagify(Z ~ X,
Z ~ Y,
W ~ Z,
coords = dag6) -> dagified_collider_b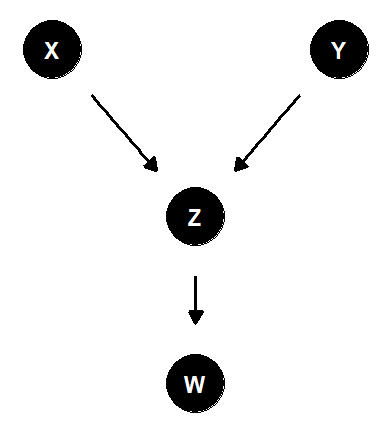
図3.9: 合流点の例2
実際にこれに基づいてデータを生成して分布をみてみると、\(X\)と\(Y\)に有意な相関はない(=独立である)ことが確かめられる。また、\(Z\)と\(W\)はどちらも\(X\), \(Y\)と有意な相関がある(=従属)。
set.seed(191)
N <- 500
X <- rpois(N, 3.5)
Y <- rnorm(N, 10, 1.5)
Z <- rpois(N, 0.8*X + 0.75*Y - 2)
W <- rnorm(N, 0.4*Z+1.2, 0.5)
d <- data.frame(X=X,Y=Y,Z=Z,W=W)ggpairs(d)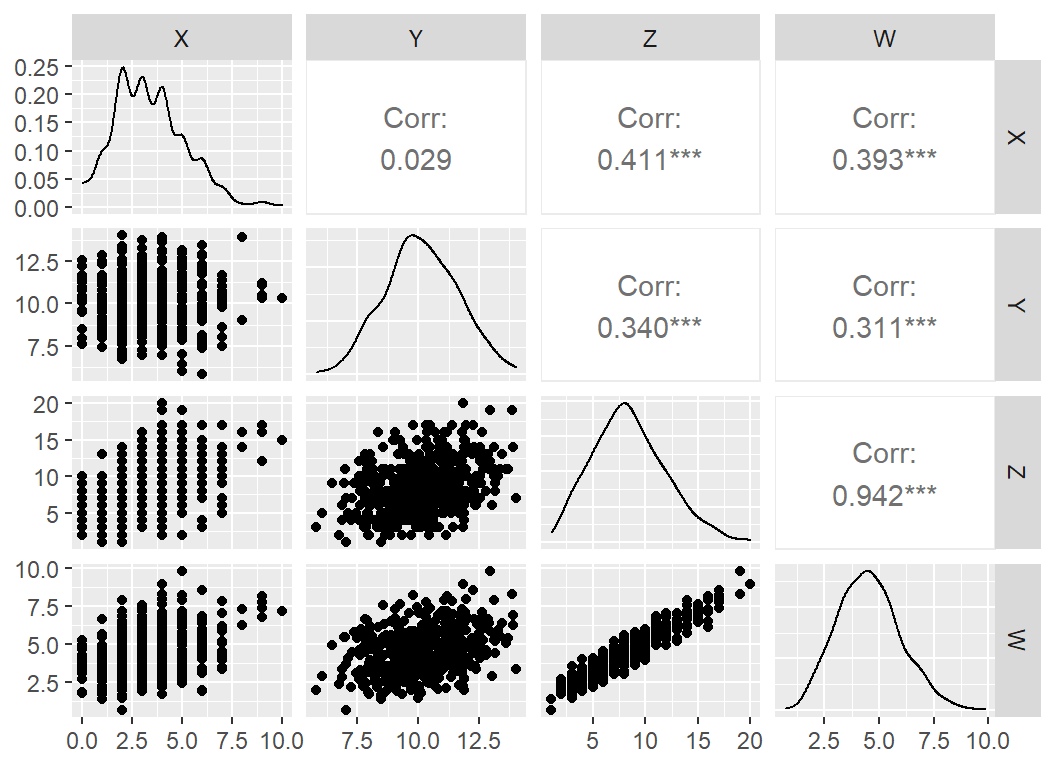
図3.10: 合流点の子を含む経路におけるX, Y, Z, Wの間の関係
一方、\(Z\)またはその子孫である\(W\)を統制した場合の\(X\)と\(Y\)の偏相関係数を調べると、いずれも小さいが有意な相関が現れる(=条件付き従属)。
\(Z\)を統制
pcor.test(d$X,d$Y,d$Z)## estimate p.value statistic n gp Method
## 1 -0.1296674 0.003713279 -2.915352 500 1 pearson\(W\)を統制
pcor.test(d$X,d$Y,d$W)## estimate p.value statistic n gp Method
## 1 -0.1068466 0.0169576 -2.395699 500 1 pearson3.2 d分離性(d-separation)
一般的な因果モデル(ダイアグラム)は、以上で見た3つのパターンより複雑であることが多い。具体的には、多くのモデルにおいて変数間を結ぶ道は複数存在し、それぞれの道は様々な連鎖、分岐、合流点を通過している。
ここでは、このように複雑なモデルにおいても変数間の独立/従属を判断するため、前節までに学んだことをもとにd-分離(d-separation)という概念を導入する。2つのノード(変数)がd分離されるとき、それらの変数は独立であるといえる。
d分離の定義 (Pearl et al. 2016)
以下の1または2が成り立つとき、グラフ上で道\(p\)がノードの集合\(Z\)にブロックされているという。
- \(p\)は連鎖経路\(A \rightarrow B \rightarrow C\)または分岐経路\(A \leftarrow B \rightarrow C\)を含み、中央のノードが\(Z\)に含まれる(= \(B\)について条件付けしている)
- \(p\)は合流点\(A \rightarrow B \leftarrow C\)を含み、合流点\(B\)とその全ての子孫が\(Z\)に含まれない(= \(Z\)とその子孫で条件付けしない)
\(Z\)が\(X\)と\(Y\)の間の道をすべてブロックするとき、\(Z\)が与えられた下で\(X\)と\(Y\)はd分離しているという。
一方で、\(X\)と\(Y\)がd分離されていないとき、\(X\)と\(Y\)はd連結であるという。
例1. 合流点とその子、分岐点を持つ因果ダイアグラム
dag7 <- tibble(name = c("X","Z","Y","W","Uz","Uw","Ux","Uy","U","Uu"),
x = c(3, 1, 4,2,1,2,3,4,2,0.5),
y = c(3,3,3,2,4,3.5,4,4,1,1.5))
dagify(X ~ Ux,
Z ~ Uz,
Y ~ X + Uy,
W ~ Z + Uw + X,
U ~ W + Uu,
coords = dag7) -> dagified_dsep1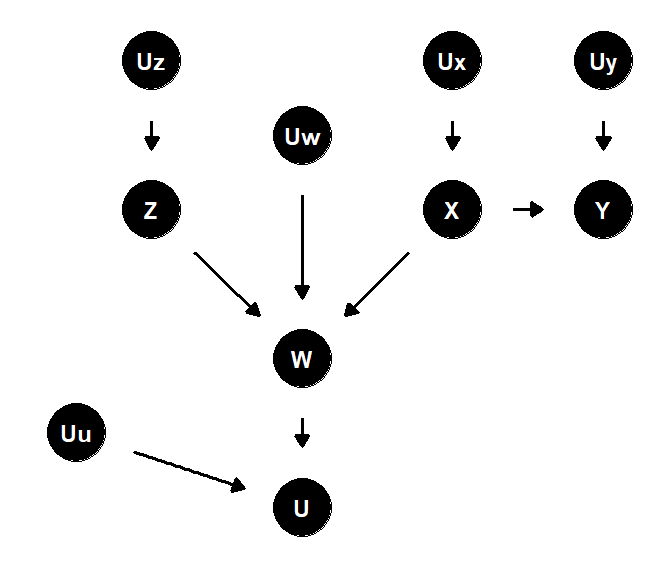
図3.11: 合流点とその子、分岐点を持つ因果ダイアグラム
\(\underline Z\)と\(\underline Y\)について
- \(Z\)と\(Y\)を結ぶ道は合流点 \(W\)を含むので全てブロックされている(= d分離されている)。しかし、\(W\)について条件付けすると\(Z\leftarrow W \rightarrow X\)がブロックされなくなり、\(Z\)は\(X\)の子である\(Y\)ともd連結になる(= 従属)。これは、\(W\)の子である\(U\)について条件付けしても同様。
- しかし、\(W\)に加えて\(X\)も条件付けすると、\(W \leftarrow X \rightarrow Y\)の分岐経路がブロックされるので、\(Z\)と\(Y\)はd分離されたままである。
Rでは、\(Z\)と\(Y\)がそれぞれの変数で条件づけられたときにd分離されるかを以下のように調べられる。
## Wで条件付け
dseparated(dagified_dsep1, "Z","Y", "W")## [1] FALSE## WとXで条件付け
dseparated(dagified_dsep1, "Z","Y", c("W","X"))## [1] TRUE例2. 図3.11に\(Z\)と\(Y\)の間の分岐経路を加えたもの
dag8 <- tibble(name = c("X","Z","Y","W","Uz","Uw","Ux","Uy","U","Uu","T","Ut"),
x = c(3, 1, 4,2,1,1.8,2.25,4,2,0.5,2.5,2.5),
y = c(3.3,3,3,2,4,3.2,3.2,4,1,1.5,3.9,4.5))
dagify(T ~ Ut,
X ~ Ux,
Z ~ T + Uz,
Y ~ X + T + Uy,
W ~ Z + Uw + X,
U ~ W + Uu,
coords = dag8) -> dagified_dsep2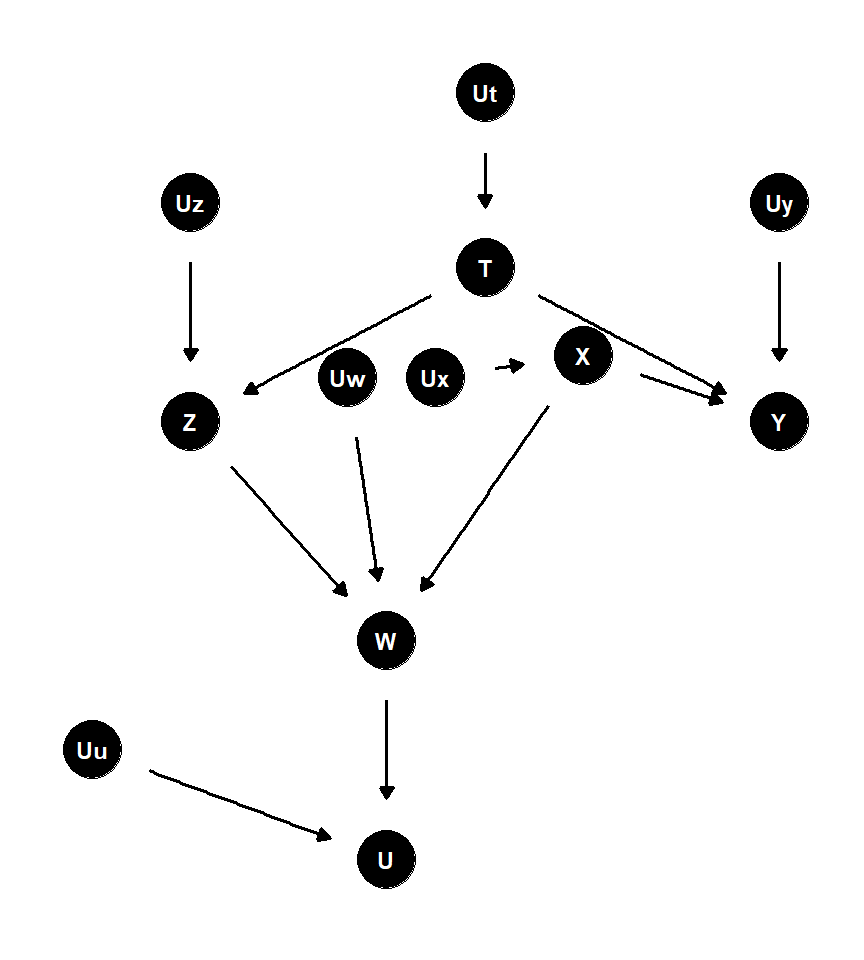
図3.12: 先のグラフにZとYの間の分岐経路を加えたもの
\(\underline Z\)と\(\underline Y\)について
- \(Z\)と\(Y\)の間に分岐経路ができたことで、何も条件付けなければ\(Z\)と\(Y\)は従属になる(= d連結)。
- \(T\)について条件付ければ、\(Z\)と\(Y\)の間の道はブロックされ、d分離される。
- \(T\)に加えて\(W\)について条件づけると、\(Z \leftarrow T \rightarrow Y\)はブロックされるが、\(Z \rightarrow W \leftarrow X \rightarrow Y\)は開いてしまうので、d連結になる。
- さらに\(X\)も加えて条件付けすれば、再びd分離される。
Rでも確かめられる。
## Tで条件付け
dseparated(dagified_dsep2, "Z","Y", "T")## [1] TRUE## TとWで条件付け
dseparated(dagified_dsep2, "Z","Y", c("T","W"))## [1] FALSE## T, W, Xで条件付け
dseparated(dagified_dsep2, "Z","Y", c("T","W","X"))## [1] TRUE練習問題
- 図3.13で隣接していない変数の組それぞれについて、どの変数の集合で条件付き独立となるか
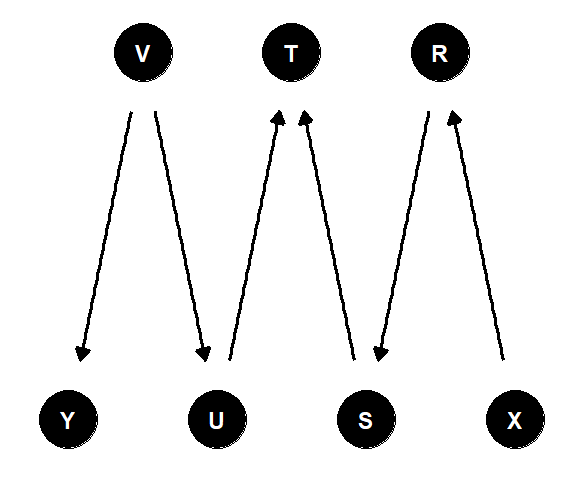
図3.13: 練習問題1の因果ダイアグラム
A. 答えは以下の8通りである。
- \(Y\), \(V\), \(U\)は分岐経路であり、\(Y\)と\(U\)を結ぶ道は1つしかないので、\(Y \mathop{\perp\!\!\!\!\perp} U|V\)
- \(V\), \(U\), \(T\)は連鎖経路であり、\(V\)と\(T\)を結ぶ道は1つずつしかないので、\(V \mathop{\perp\!\!\!\!\perp} T|U\)
- \(X\), \(R\), \(S\), \(T\)は連鎖経路であり、道は一つしかない。よって、\(X \mathop{\perp\!\!\!\!\perp} T|R, X \mathop{\perp\!\!\!\!\perp} T|S, X \mathop{\perp\!\!\!\!\perp} S|R, R \mathop{\perp\!\!\!\!\perp} T|S\)
- \(V\)は\(Y\)と\(T\)のいずれの原因にもなっているので、\(Y\)と\(T\)はおそらく従属である。しかし、\(U\)で条件づけると\(V\)と\(T\)が独立になり、結果的に\(V\)の子である\(Y\)と\(T\)も独立になる(\(Y \mathop{\perp\!\!\!\!\perp} T|U\))
- \(V\)で条件づけると\(Y\)と\(U\)が独立になり、結果的に\(U\)の子である\(T\)も\(Y\)と独立になる(\(Y \mathop{\perp\!\!\!\!\perp}T|U\))
Rでは、すべての独立/条件付き独立の変数の集合は以下のように求められる。
# impliedConditionalIndependencies(dagified_prac1)
- 図3.13のモデルからデータを生成し、線形方程式\(Y = a + bX + cZ\)をあてはめる。傾きbを0にするには\(Z\)にどの変数を選べばよいか。
A. \(Z\)の下で\(X\)と\(Y\)が条件付き独立(d分離)になればよい。\(T\)以外は条件づけてもd分離されるので、\(T\)以外ならどれでもよい。
## 各変数で条件づけたときにXとYがd分離されるか調べる
sapply( names(dagified_prac1), function(Z) dseparated(dagified_prac1,"X","Y",Z) )## R S T U V X Y
## TRUE TRUE FALSE TRUE TRUE TRUE TRUE実際にモデルからデータを生成して確認する。simulateSEM()関数を用いると、モデルに基づいてデータを生成することができる。
d_prac1 <- simulateSEM(# モデルの因果ダイアグラム
dagified_prac1,
# パス係数を0.7に設定する
b.lower = 0.7,
b.upper = 0.7,
N = 5000)確かに\(T\)で条件づけると\(X\)の係数は0でない。
lm(Y ~ X + T, data = d_prac1) %>%
model_parameters() %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | 0.011 | 0.013 | 0.391 |
| X | -0.136 | 0.014 | 0.000 |
| T | 0.405 | 0.014 | 0.000 |
他の変数(例えば\(S\)や\(V\))では\(X\)の係数はほぼ0になる。
lm(Y ~ X + S, data = d_prac1) %>%
model_parameters() %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | 0.011 | 0.014 | 0.417 |
| X | 0.000 | 0.016 | 0.995 |
| S | 0.015 | 0.016 | 0.351 |
lm(Y ~ X + V, data = d_prac1) %>%
model_parameters() %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | 0.007 | 0.01 | 0.497 |
| X | 0.004 | 0.01 | 0.660 |
| V | 0.695 | 0.01 | 0.000 |
- 図3.14で隣接していない変数の組それぞれについて、どの変数の集合で条件付き独立となるか
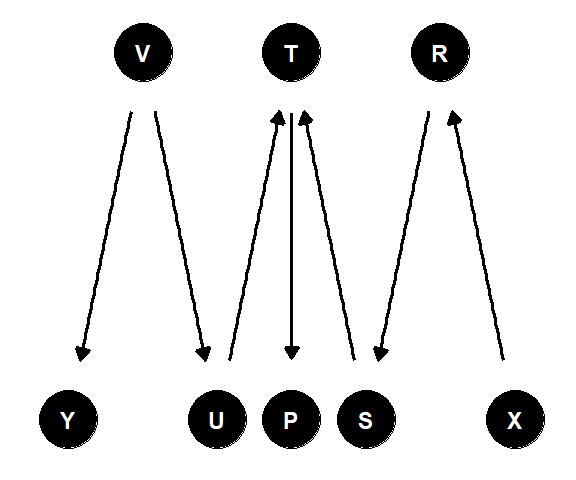
図3.14: 練習問題3の因果ダイアグラム
A. 問1で挙げた組み合わせに加えて、以下でも条件付き独立になる。
- \(P\mathop{\perp\!\!\!\!\perp}U|T\) (連鎖経路)
- \(P\mathop{\perp\!\!\!\!\perp}V|T, P\mathop{\perp\!\!\!\!\perp}V|U\) (連鎖経路)
- \(P\mathop{\perp\!\!\!\!\perp}S|T\) (連鎖経路)
- \(P\mathop{\perp\!\!\!\!\perp}R|S, P\mathop{\perp\!\!\!\!\perp}R|T\) (連鎖経路)
- \(P\mathop{\perp\!\!\!\!\perp}X|R,P\mathop{\perp\!\!\!\!\perp}X|S, P\mathop{\perp\!\!\!\!\perp}X|T\) (連鎖経路)
- \(P\mathop{\perp\!\!\!\!\perp}Y|V,P\mathop{\perp\!\!\!\!\perp}Y|U, P\mathop{\perp\!\!\!\!\perp}Y|T\) (分岐経路+連鎖経路)
以下でも確かめられる。
#impliedConditionalIndependencies(dagified_prac2)
- 図3.14のモデルで、方程式\(Y = a + bX + cR + dS + eT + fP\)をあてはめると、どの係数が0になるか。
A. \(X,R,S,T,P\)について、これらの変数が全て条件づけられたときに\(Y\)とd分離されるかを検討すればよい。以下のようにして\(X, R, S, T, P\)で条件づけたときに\(Y\)とd分離される変数を全て求められる。
\(T\)と\(S\)以外の変数はd分離されるので、係数が0になるのは\(T\)と\(S\)以外の変数である。
dseparated(dagified_prac2, "Y", list(), c("X","R","S","T","P"))## [1] "P" "R" "X"実際にモデルからデータを生成して確認する。
たしかに、\(T\)と\(S\)以外は係数がほぼ0になる。
d_prac2 <- simulateSEM(# モデルの因果ダイアグラム,
dagified_prac2,
# パス係数を0.7に設定する
b.lower = 0.7,
b.upper = 0.7,
N = 5000)
lm(Y ~ X + R + S + T + P, data = d_prac2) %>%
model_parameters() %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | -0.015 | 0.013 | 0.249 |
| X | -0.013 | 0.018 | 0.449 |
| R | -0.017 | 0.022 | 0.430 |
| S | -0.437 | 0.022 | 0.000 |
| T | 0.679 | 0.022 | 0.000 |
| P | -0.007 | 0.018 | 0.698 |
- 以下のダイアグラムについて、隣接しないノード全ての組について、その2つをd分離する変数の集合を答えよ(最小限必要な変数のみでよい)。
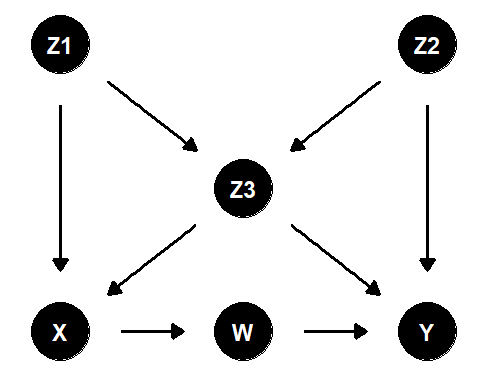
図3.15: 練習問題5の因果ダイアグラム
A. 以下の通り
- \(X\)と\(Y\): \(\{ W, Z_3, Z_1 \},\{ W, Z_3, Z_2 \}\)
▶ \(X\)と\(Y\)の間の道をブロックするため、\(W\)\(とZ3\)は必ず入れる必要あり。しかし\(Z_3\)(= 合流点)を入れると\(X \leftarrow Z_1 \rightarrow Z_3 \leftarrow Z_2 \rightarrow Y\)がブロックされなくなるため、加えて\(Z_1\)または\(Z_2\)も条件づける必要がある。
- \(Y\)と\(Z_1\): \(\{ Z_3, Z_2, X \}, \{ Z_3, Z_2, W \}\)
▶ \(Z_1 \rightarrow Z_3 \rightarrow T\)と\(Z_1 \rightarrow X \rightarrow W \rightarrow Y\)をブロックするため\(Z_3\)と\(X\)または\(W\)は必ず条件づける必要あり。しかし\(Z\)を条件づけると\(Z_1 \rightarrow Z_3 \leftarrow Z_2 \rightarrow Y\)がブロックされなくなるため、\(Z_2\)も条件づける必要がある。
- \(X\)と\(Z_2\): \(\{ Z_1, Z_3 \}\)
- \(W\)と\(Z_2\): \(\{ X \}\), \(\{ Z_3, Z_1 \}\)
- \(W\)と\(Z_1\): \(\{ X \}\)
- \(W\)と\(Z_3\): \(\{ X \}\)
以下でも確かめられる。
#impliedConditionalIndependencies(dagified_prac3)
- 図3.15のモデルで\(Z_3\)の値から\(Z_2\)の値を予測する。\(W\)の値も使った方がよりよい予測になるか?
一般に、\(Z_2\)とd分離されていない(= 独立でない)限りは、どの変数を入れても予測は向上する。しかし、\(W\)は\(Z_3\)で条件づけたとき\(Z_2\)とd分離されるため、\(W\)を入れても予測は良くならないはずである。
これは以下のシミュレーションでも確かめられる。
d_prac3 <- simulateSEM(dagified_prac3,
# パス係数を0.4に設定する
b.lower = 0.4,
b.upper = 0.4,
N = 10000)
## Z3のみ
m_without_W <- lm(Z2 ~ Z3, data = d_prac3)
## Z3 + W
m_with_W <- lm(Z2 ~ Z3 + W, data = d_prac3)
## Z3 + Y
m_with_Y <- lm(Z2 ~ Z3 + Y, data = d_prac3)線形モデルの決定係数\(R^2\)を計算すると、\(W\)を入れても入れなくてもほとんど変わらない。
一方、\(Z_3\)とd連結している(従属な)\(Y\)を入れると予測は向上する。
## 決定係数を比較
compare_performance(m_without_W,m_with_W, m_with_Y) %>%
data.frame() %>%
dplyr::select(1,7,8) %>%
kable()| Name | R2 | R2_adjusted |
|---|---|---|
| m_without_W | 0.1559857 | 0.1559012 |
| m_with_W | 0.1560372 | 0.1558684 |
| m_with_Y | 0.3449176 | 0.3447865 |
3.3 モデル検定と因果探索
実際の分析では、モデルから想定される条件付き独立が実際のデータでも見られるかによって、因果モデルが正しいものかを検証していく。例えば、図3.15では\(W\)と\(Z_{1}\)は\(X\)によりd分離されている。よって、もしこの因果モデルが正しいとすれば、以下の式で回帰分析を行ったときに、係数\(r_1\)は0になるはずである。
\[
W = r_{X}X + r_{1}Z_1
\]
もし\(r_1\)が0でないならば、因果モデルは間違っていることになる。また、真のモデルでは\(W\)と\(Z_1\)の間に\(X\)ではd分離されていない道があるはずだということになる。このように、モデルにある全てのd分離の条件がデータの条件付き独立と一致するかを検討することで、モデルの検証を行える。
d分離性を利用したモデルの検証には以下の利点がある。
- 変数の関係を表す関数がどのような形でもグラフの構造のみから検証可能(= ノンパラメトリック)
- 局所的なモデルの修正を行える
なお、最終的には1つではなく、複数のモデルまでしか絞り込めないのことの方が多い。これは、データにある独立性/従属性と矛盾しないような因果モデルは複数存在する場合が多いからである。このようなモデルはmarcov equivalentであるという。
例えば、以下のグラフで表されるモデルは全てmarcov equivalentである(つまり、変数間の独立/従属関係がすべて同じ)。
Marcov equivalentなモデルはggdag_equivalent_dags()を用いて求められる。
dagify(X ~ Z1,
Z2 ~ Z1,
Y ~ Z2 + W + X,
W ~ X ) -> dagified_prac4
ggdag_equivalent_dags(dagified_prac4,node_size =9, text_size = 3)+
theme_dag()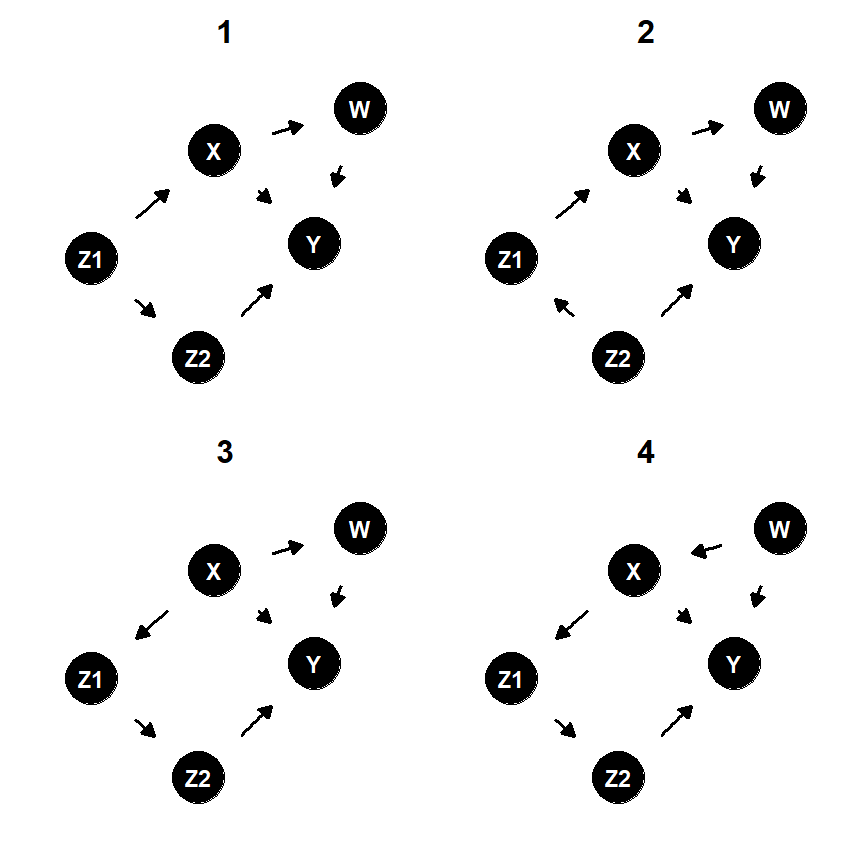
図3.16: Marcov equivalentなモデルの例
練習問題
- 図3.15のモデルで、もしいずれかの係数が0でないときにモデルが誤りになる\(Y\)の回帰式を1つ書け
たとえば、図3.15のモデルで\(X\)と\(Y\)は\(Z_2,Z_3,W\)によってd分離される。よって、以下の回帰式で\(X\)の係数が0でなければモデルは誤りになる。
\[ Y = a + bX + cZ_1 + dZ_3 + eW \] 実際、モデルから生成したデータを用いて分析すると\(X\)の係数はほぼ0になる。
lm(Y ~ X + Z2 + Z3 + W, data = d_prac3) %>%
model_parameters() %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | -0.001 | 0.005 | 0.874 |
| X | 0.004 | 0.007 | 0.561 |
| Z2 | 0.401 | 0.006 | 0.000 |
| Z3 | 0.393 | 0.007 | 0.000 |
| W | 0.399 | 0.006 | 0.000 |
- 図3.15のモデルで、\(X\)が観測されていない場合に、もしいずれかの係数が0でないときにモデルが誤りになる\(Z_3\)の回帰式を1つ書け
\(X\)が未観測のとき、条件付き独立になるのは以下の場合である。
\(Z_3\)と独立な変数はないため、係数が0になるような変数はない。
## xが未観測であることにする
latents(dagified_prac3) <- "X"
impliedConditionalIndependencies(dagified_prac3)## W _||_ Z2 | Z1, Z3
## Y _||_ Z1 | W, Z2, Z3
## Z1 _||_ Z2
- 図3.15のモデルで問1のような回帰式がいくつあればモデルを完全に検証したことになるか。
このような回帰式の集合はbasis setと呼ばれ、以下のように求められる。
最後の2つは同じ2変数についてのものなので、4つの回帰式を検証すればよい。
## Xが未観測という情報を消す
latents(dagified_prac3) <- c()
impliedConditionalIndependencies(dagified_prac3, type = "basis.set")## W _||_ Z1, Z2, Z3 | X
## X _||_ Z2 | Z1, Z3
## Y _||_ X, Z1 | W, Z2, Z3
## Z1 _||_ Z2
## Z2 _||_ Z1例えば、一行目は以下の回帰式で検証できる。
\(X\)で条件づけたとき、\(Z_1,Z_2,Z_3\)の係数が全て0になればよい。
\[ W = a + bX + cZ_1 + dZ_2 + eZ_3 \]
実際、モデルから生成したデータを用いて分析すると\(Z_1, Z_2, Z_3\)の係数はほぼ0になる。
lm(W ~ X + Z1 + Z2 + Z3, data = d_prac3) %>%
model_parameters() %>%
data.frame() %>%
dplyr::select(1,2,3,9) %>%
kable(digits = 3, align = "lccc")| Parameter | Coefficient | SE | p |
|---|---|---|---|
| (Intercept) | 0.001 | 0.009 | 0.932 |
| X | 0.383 | 0.012 | 0.000 |
| Z1 | 0.005 | 0.011 | 0.629 |
| Z2 | 0.019 | 0.010 | 0.064 |
| Z3 | -0.007 | 0.012 | 0.558 |
References
従属にならない場合はごく少数の特殊な場合だけなので、基本的には従属であると考えてよい。分岐経路と合流点の従属関係についても同様である。↩︎